En el capítulo anterior estudiamos Random Forest, un método de ensamble que construye múltiples árboles de decisión de manera paralela e independiente, promediando sus predicciones para reducir la varianza. Random Forest es robusto, fácil de usar y funciona bien en una amplia variedad de problemas. Sin embargo, existe otra familia de métodos de ensamble que adopta una filosofía radicalmente diferente: los métodos de boosting.
A diferencia de los métodos de bagging, que construyen modelos independientes en paralelo, el boosting construye una secuencia de modelos de forma iterativa y adaptativa. Cada nuevo modelo se enfoca específicamente en corregir los errores cometidos por los modelos anteriores. Esta idea es intuitiva: si un estudiante está aprendiendo un tema difícil, no repite el mismo ejercicio una y otra vez esperando mejorar (como haría bagging). En su lugar, identifica sus errores, presta atención especial a los conceptos que no comprende bien, y practica específicamente en esas áreas débiles. Exactamente así funciona el boosting: es un proceso de aprendizaje adaptativo que se enfoca iterativamente en los casos más difíciles.
Esta estrategia ha demostrado ser extraordinariamente exitosa en la práctica. Los algoritmos de boosting, particularmente sus implementaciones modernas como XGBoost, LightGBM y CatBoost, dominan las competencias de machine learning como Kaggle, son ampliamente utilizados en la industria para problemas de predicción con datos estructurados (tablas), y han ganado reputación como los algoritmos de aprendizaje supervisado más efectivos para este tipo de datos. En este capítulo exploraremos por qué el boosting es tan poderoso, cómo funcionan sus principales variantes, y cómo aplicarlo efectivamente en problemas reales.
El Concepto Central del Boosting
La idea fundamental del boosting se puede resumir en una fórmula simple pero poderosa:
Un aprendiz débil (weak learner) es un modelo que tiene un desempeño apenas mejor que el azar. Por ejemplo, en clasificación binaria, un modelo que acierta el 51% de las veces es un aprendiz débil (comparado con 50% de adivinar al azar). En la práctica, los árboles de decisión muy simples, llamados decision stumps (árboles de profundidad 1, con una sola división), son los aprendices débiles más comunes en boosting.
Aprendiz Débil (Weak Learner)
Un aprendiz débil es un modelo de predicción cuyo desempeño es ligeramente mejor que adivinar al azar, pero no necesariamente muy preciso. La teoría matemática del boosting garantiza que combinando múltiples aprendices débiles de forma adecuada, es posible construir un modelo arbitrariamente preciso, asumiendo que cada aprendiz débil es mejor que el azar.
Los árboles de decisión poco profundos (típicamente profundidad 1-3) son los aprendices débiles más utilizados en boosting porque:
Son rápidos de entrenar
Tienen alto sesgo pero baja varianza
Pueden capturar interacciones entre variables
Son diferenciables (importante para gradient boosting)
El boosting construye un modelo final como una combinación ponderada de estos aprendices débiles:
\[
F(x) = \sum_{m=1}^{M} \alpha_m h_m(x)
\]
donde:
\(F(x)\) es la predicción final del modelo de boosting
\(M\) es el número total de iteraciones (modelos débiles)
\(h_m(x)\) es el \(m\)-ésimo aprendiz débil
\(\alpha_m\) es el peso asignado al modelo \(h_m(x)\)
La magia del boosting está en cómo construimos esta secuencia. Cada nuevo modelo \(h_m\) no se entrena de manera independiente (como en bagging), sino que se enfoca específicamente en los ejemplos donde el modelo acumulado \(F_{m-1}(x) = \sum_{i=1}^{m-1} \alpha_i h_i(x)\) tiene mayor error. En otras palabras:
Iteración 1: Entrenamos un modelo simple en todos los datos
Iteración 2: Identificamos dónde falló el primer modelo y entrenamos un segundo modelo que se enfoca en esos errores
Iteración 3: Identificamos dónde falló la combinación de los dos primeros modelos y entrenamos un tercer modelo para corregir
…y así sucesivamente
Este proceso adaptativo y secuencial es lo que distingue fundamentalmente al boosting de otros métodos de ensamble.
Diferencia Clave: Boosting vs Bagging
La diferencia fundamental entre boosting y bagging se resume en dos dimensiones:
Construcción:
Bagging (Random Forest): Construye árboles en paralelo e independientemente. Cada árbol se entrena en una muestra bootstrap diferente sin comunicación entre ellos.
Boosting: Construye modelos secuencialmente y adaptativamente. Cada nuevo modelo depende explícitamente de los errores de los modelos anteriores.
Boosting: Reduce sesgo combinando modelos simples (árboles superficiales) que corrigen iterativamente los errores
Esta diferencia tiene consecuencias importantes:
Bagging es fácilmente paralelizable (todos los árboles pueden entrenarse simultáneamente)
Boosting debe entrenarse secuencialmente (cada modelo necesita los resultados del anterior)
Bagging es muy robusto al ruido y outliers
Boosting puede sobreajustar si no se regula cuidadosamente, especialmente en datos ruidosos
Intuición Visual: Boosting en Acción
Para entender cómo funciona el boosting en la práctica, consideremos un problema de regresión simple en una dimensión. Generaremos datos sintéticos con una función no lineal y veremos cómo el boosting construye iterativamente un modelo cada vez más preciso.
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.ensemble import GradientBoostingRegressorfrom sklearn.tree import DecisionTreeRegressor# Configurar el estilo de las gráficasplt.style.use('default')np.random.seed(42)# Generar datos sintéticos 1Ddef true_function(x):"""Función verdadera: combinación de seno y tendencia lineal"""return np.sin(2* x) +0.1* x + np.cos(x)# Generar datosn_samples =150X_train = np.random.uniform(-3, 3, n_samples)y_train = true_function(X_train) + np.random.normal(0, 0.2, n_samples)# Puntos para visualizaciónX_plot = np.linspace(-3, 3, 300).reshape(-1, 1)y_true = true_function(X_plot.ravel())# Entrenar modelos con diferente número de iteracionessingle_tree = DecisionTreeRegressor(max_depth=2, random_state=42)single_tree.fit(X_train.reshape(-1, 1), y_train)boosting_5 = GradientBoostingRegressor( n_estimators=5, max_depth=2, learning_rate=0.5, random_state=42)boosting_5.fit(X_train.reshape(-1, 1), y_train)boosting_20 = GradientBoostingRegressor( n_estimators=20, max_depth=2, learning_rate=0.5, random_state=42)boosting_20.fit(X_train.reshape(-1, 1), y_train)# Prediccionesy_single = single_tree.predict(X_plot)y_boost_5 = boosting_5.predict(X_plot)y_boost_20 = boosting_20.predict(X_plot)# Crear figura con 4 subgráficasfig, axes = plt.subplots(2, 2, figsize=(12, 8))# (a) Datos originalesax = axes[0, 0]ax.scatter(X_train, y_train, alpha=0.5, s=30, edgecolors='k', linewidths=0.5, label='Datos de entrenamiento')ax.plot(X_plot, y_true, 'g-', linewidth=2, label='Función verdadera')ax.set_xlabel('x', fontsize=11)ax.set_ylabel('y', fontsize=11)ax.set_title('(a) Datos originales', fontsize=12, fontweight='bold')ax.legend(fontsize=9)ax.grid(True, alpha=0.3)# (b) Árbol único (aprendiz débil)ax = axes[0, 1]ax.scatter(X_train, y_train, alpha=0.3, s=30, edgecolors='k', linewidths=0.5, label='Datos')ax.plot(X_plot, y_true, 'g-', linewidth=1.5, alpha=0.5, label='Función verdadera')ax.plot(X_plot, y_single, 'r-', linewidth=2.5, label='Árbol único (débil)')ax.set_xlabel('x', fontsize=11)ax.set_ylabel('y', fontsize=11)ax.set_title('(b) Un solo aprendiz débil (árbol profundidad=2)', fontsize=12, fontweight='bold')ax.legend(fontsize=9)ax.grid(True, alpha=0.3)# Calcular y mostrar MSEmse_single = np.mean((y_train - single_tree.predict(X_train.reshape(-1, 1)))**2)ax.text(0.05, 0.95, f'MSE = {mse_single:.3f}', transform=ax.transAxes, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5), fontsize=9)# (c) Boosting con 5 iteracionesax = axes[1, 0]ax.scatter(X_train, y_train, alpha=0.3, s=30, edgecolors='k', linewidths=0.5, label='Datos')ax.plot(X_plot, y_true, 'g-', linewidth=1.5, alpha=0.5, label='Función verdadera')ax.plot(X_plot, y_boost_5, 'b-', linewidth=2.5, label='Boosting (5 iteraciones)')ax.set_xlabel('x', fontsize=11)ax.set_ylabel('y', fontsize=11)ax.set_title('(c) Después de 5 iteraciones de boosting', fontsize=12, fontweight='bold')ax.legend(fontsize=9)ax.grid(True, alpha=0.3)# Calcular y mostrar MSEmse_boost5 = np.mean((y_train - boosting_5.predict(X_train.reshape(-1, 1)))**2)ax.text(0.05, 0.95, f'MSE = {mse_boost5:.3f}', transform=ax.transAxes, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='lightblue', alpha=0.5), fontsize=9)# (d) Boosting con 20 iteracionesax = axes[1, 1]ax.scatter(X_train, y_train, alpha=0.3, s=30, edgecolors='k', linewidths=0.5, label='Datos')ax.plot(X_plot, y_true, 'g-', linewidth=1.5, alpha=0.5, label='Función verdadera')ax.plot(X_plot, y_boost_20, 'purple', linewidth=2.5, label='Boosting (20 iteraciones)')ax.set_xlabel('x', fontsize=11)ax.set_ylabel('y', fontsize=11)ax.set_title('(d) Después de 20 iteraciones de boosting', fontsize=12, fontweight='bold')ax.legend(fontsize=9)ax.grid(True, alpha=0.3)# Calcular y mostrar MSEmse_boost20 = np.mean((y_train - boosting_20.predict(X_train.reshape(-1, 1)))**2)ax.text(0.05, 0.95, f'MSE = {mse_boost20:.3f}', transform=ax.transAxes, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='plum', alpha=0.5), fontsize=9)plt.tight_layout()plt.show()
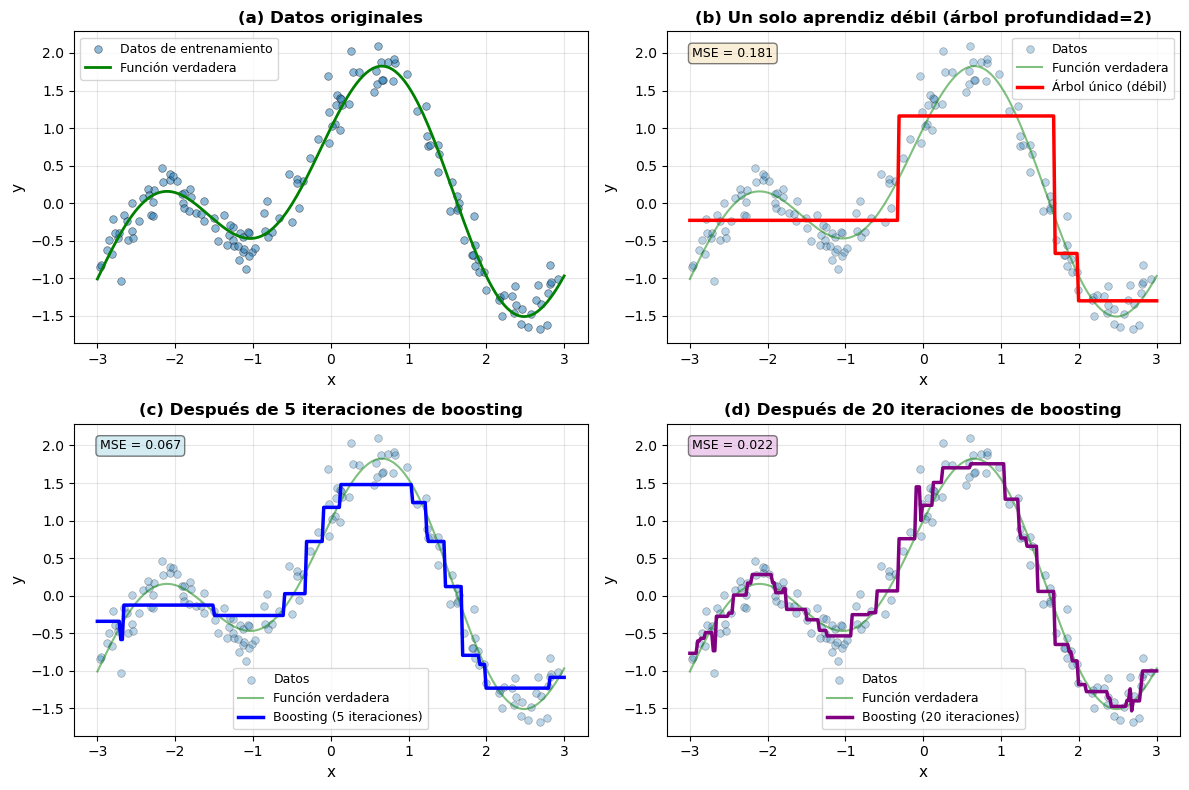
Figura 10.1: Demostración visual del proceso de boosting en un problema de regresión 1D. (a) Los datos originales con una función no lineal más ruido. (b) Un único árbol de decisión poco profundo (aprendiz débil) proporciona una aproximación muy burda. (c) Después de 5 iteraciones de boosting, el modelo comienza a capturar la forma general de los datos. (d) Después de 20 iteraciones, el modelo se ajusta bien a la función subyacente, corrigiendo progresivamente los errores de las iteraciones anteriores.
Esta visualización ilustra el proceso fundamental del boosting:
Panel (a): Los datos originales muestran una relación no lineal con ruido. Un modelo lineal simple tendría alto sesgo en este problema.
Panel (b): Un único árbol de profundidad 2 (nuestro aprendiz débil) proporciona una aproximación muy burda con forma de escalera. Este modelo tiene alto sesgo (MSE alto) - claramente no captura bien la complejidad de los datos.
Panel (c): Después de 5 iteraciones, cada una agregando un nuevo árbol que corrige los errores de la combinación anterior, el modelo comienza a capturar la tendencia general. El MSE ha disminuido significativamente.
Panel (d): Con 20 iteraciones, el modelo final se ajusta muy bien a la función verdadera. Cada iteración agregó correcciones incrementales, construyendo colaborativamente una función compleja a partir de piezas simples.
Veamos ahora cómo evolucionan los residuales (errores) a través de las iteraciones, que es donde realmente se aprecia la naturaleza adaptativa del boosting:
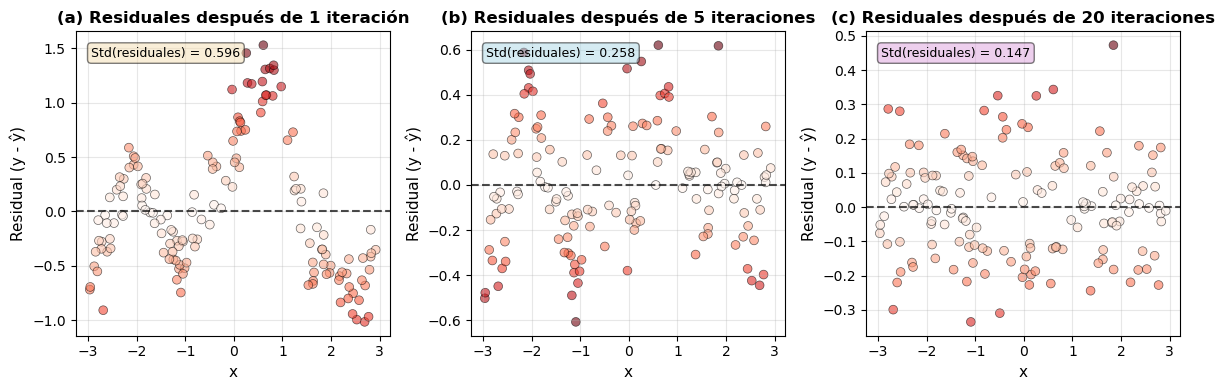
Figura 10.2: Evolución de los residuales durante el proceso de boosting. Los residuales son las diferencias entre los valores verdaderos y las predicciones del modelo acumulado. (a) Después de la primera iteración, los residuales son grandes y estructurados. (b) Después de 5 iteraciones, los residuales se han reducido considerablemente. (c) Después de 20 iteraciones, los residuales son pequeños y cercanos a cero, indicando que el modelo ha aprendido la función subyacente. Cada nueva iteración se enfoca en reducir estos residuales.
Los residuales nos muestran la historia completa del boosting:
Después de 1 iteración: Los residuales son grandes (desviación estándar alta) y muestran patrones claros. Hay regiones donde el modelo consistentemente subestima o sobreestima.
Después de 5 iteraciones: Los residuales se han reducido considerablemente. Los patrones sistemáticos han disminuido, pero aún hay estructura que el modelo no ha capturado completamente.
Después de 20 iteraciones: Los residuales son pequeños y se distribuyen aleatoriamente alrededor de cero. Esto indica que el modelo ha aprendido la señal subyacente y lo que queda es principalmente ruido irreducible.
La lección clave: Cada nueva iteración de boosting entrena un modelo que intenta predecir estos residuales, y luego lo suma al modelo acumulado. Este proceso de “corrección iterativa de errores” es la esencia del boosting, y es lo que le permite construir modelos complejos y precisos a partir de componentes simples.
En las siguientes secciones, exploraremos los algoritmos específicos que implementan esta idea general: desde AdaBoost, el primer método práctico de boosting, hasta gradient boosting y sus implementaciones modernas que dominan el campo del machine learning para datos estructurados.
Boosting vs Bagging vs Random Forest
Ahora que comprendemos la intuición básica del boosting, es importante posicionarlo claramente frente a otros métodos de ensamble que ya conocemos: bagging y Random Forest. Aunque todos estos métodos combinan múltiples modelos base para mejorar el rendimiento, difieren fundamentalmente en cómo construyen y combinan estos modelos, y en qué tipo de error están diseñados para reducir.
Tabla Comparativa
La siguiente tabla resume las diferencias clave entre estos tres métodos de ensamble:
Característica
Bagging
Random Forest
Boosting
Construcción
Paralela
Paralela
Secuencial
Dependencia
Independiente
Independiente
Adaptativa
Objetivo principal
Reducir varianza
Reducir varianza
Reducir sesgo
Aprendices base
Fuertes (árboles profundos)
Fuertes (árboles profundos)
Débiles (árboles superficiales)
Muestreo de datos
Bootstrap de filas
Bootstrap de filas
Pesos adaptativos o full data
Muestreo de features
Todas las features
Subconjunto aleatorio
Todas las features
Riesgo de sobreajuste
Bajo
Muy bajo
Medio-Alto
Sensibilidad al ruido
Baja
Muy baja
Alta
Velocidad de entrenamiento
Rápida (paralelizable)
Rápida (paralelizable)
Más lenta (secuencial)
Velocidad de predicción
Media
Media
Rápida-Media
Interpretabilidad
Baja
Baja
Media
Implicaciones de la Construcción Paralela vs Secuencial
La diferencia entre construcción paralela (bagging/RF) y secuencial (boosting) tiene consecuencias prácticas importantes:
Paralelización:
Bagging y Random Forest pueden entrenar todos los árboles simultáneamente en múltiples núcleos/máquinas
Boosting debe entrenar cada modelo después del anterior, limitando la paralelización
En sistemas distribuidos modernos, esto puede significar diferencias de velocidad de 10-100x
Adaptación:
En bagging/RF, si un árbol comete errores, los otros árboles no lo “saben”
En boosting, cada modelo nuevo se construye específicamente para corregir los errores de los anteriores
Esto hace al boosting más “inteligente” pero también más susceptible a sobreajustar datos ruidosos
Perspectiva de Sesgo-Varianza
Para entender profundamente cuándo usar cada método, debemos revisar la descomposición del error en términos de sesgo y varianza (visto en el ?sec-principios).
Recordemos que el error esperado de predicción se puede descomponer como:
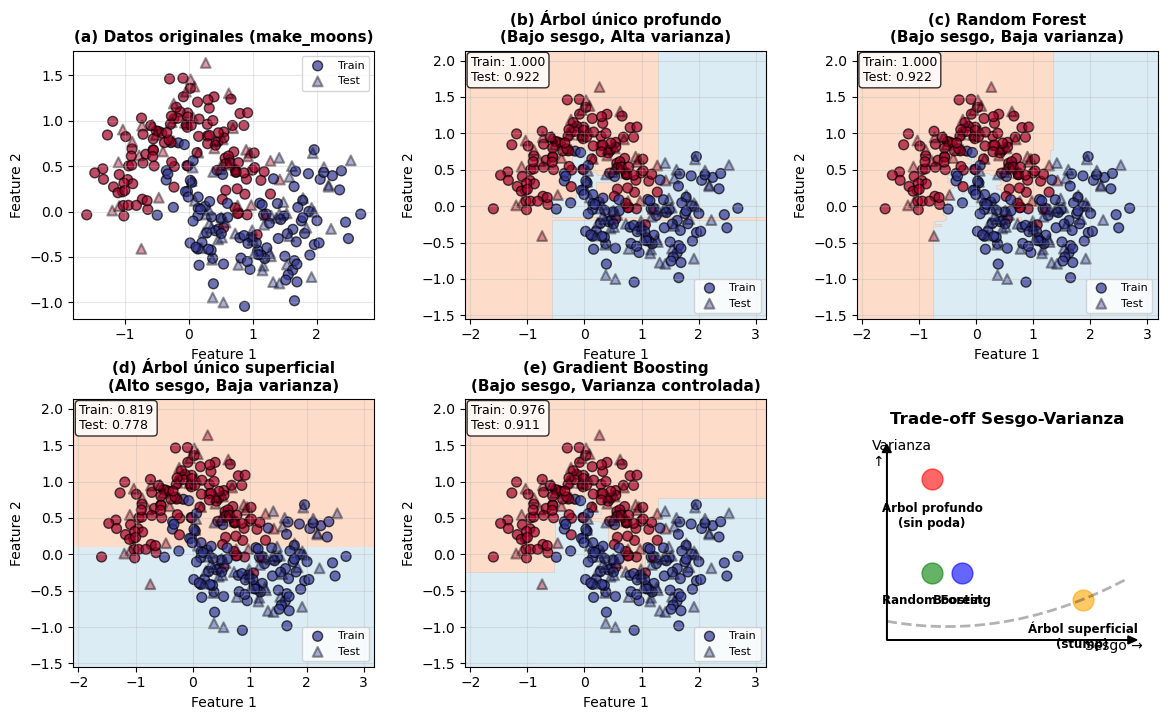
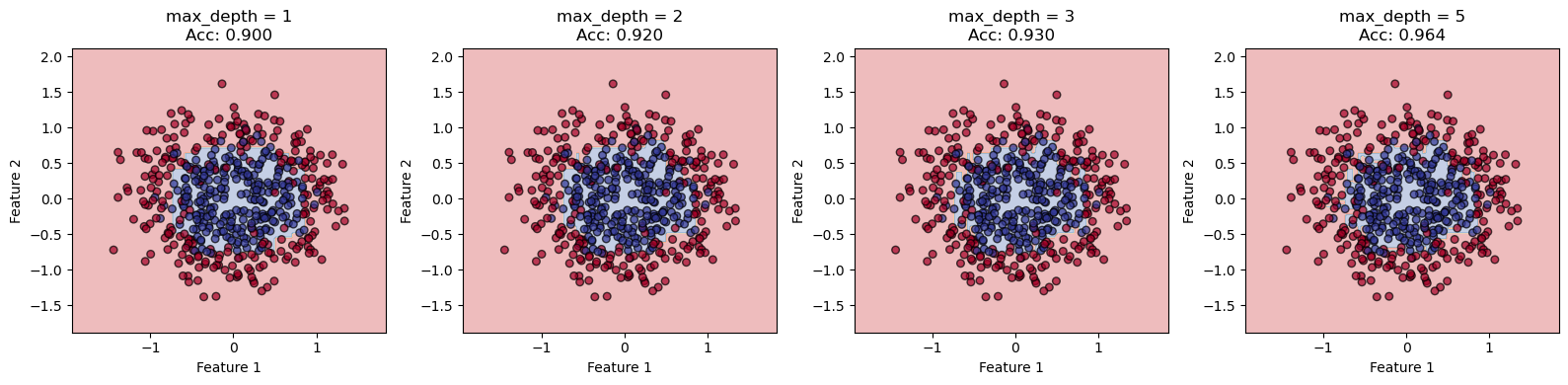
Figura 10.3: Comparación de métodos de ensamble desde la perspectiva sesgo-varianza en un problema de clasificación no lineal (make_moons). (a) Los datos tienen una estructura en forma de lunas entrelazadas con ruido. (b) Un árbol único profundo tiene bajo sesgo pero alta varianza (sobreajusta). (c) Random Forest mantiene bajo sesgo y reduce varianza significativamente. (d) Un árbol único superficial tiene alto sesgo pero baja varianza (subajusta). (e) Boosting reduce el sesgo progresivamente manteniendo la varianza controlada. Las fronteras de decisión ilustran cómo cada método equilibra este trade-off.
La visualización anterior ilustra claramente las diferencias:
Panel (b) - Árbol profundo único: La frontera de decisión es extremadamente irregular, ajustándose a cada peculiaridad de los datos de entrenamiento. Alta precisión en train (casi 1.0) pero menor en test. Esto es alta varianza y bajo sesgo.
Panel (c) - Random Forest: La frontera es suave pero captura bien la estructura en forma de luna. Precisión similar en train y test. Random Forest promedió 100 árboles profundos, reduciendo la varianza mientras mantiene bajo sesgo.
Panel (d) - Árbol superficial único: La frontera es extremadamente simple (una línea recta), incapaz de capturar la complejidad de los datos. Esto es alto sesgo y baja varianza.
Panel (e) - Gradient Boosting: La frontera captura bien la estructura no lineal sin sobreajustar excesivamente. Boosting combinó 100 árboles superficiales, cada uno corrigiendo errores del anterior, reduciendo el sesgo progresivamente.
Panel (f): El diagrama conceptual posiciona cada método en el espacio sesgo-varianza, mostrando que Random Forest y Boosting convergen a la zona de bajo error total desde direcciones opuestas.
Comparación de Curvas de Aprendizaje
Otra forma de entender las diferencias es observar cómo evoluciona el error en entrenamiento y validación a medida que agregamos más modelos al ensamble:
from sklearn.metrics import log_loss# Entrenar modelos con staged_predict para obtener predicciones en cada iteraciónrf = RandomForestClassifier(n_estimators=200, max_depth=10, random_state=42, warm_start=False)gb = GradientBoostingClassifier(n_estimators=200, max_depth=2, learning_rate=0.1, random_state=42)rf.fit(X_train, y_train)gb.fit(X_train, y_train)# Para Random Forest, necesitamos entrenar incrementalmenterf_train_errors = []rf_test_errors = []for n_trees inrange(1, 201, 5): rf_temp = RandomForestClassifier(n_estimators=n_trees, max_depth=10, random_state=42) rf_temp.fit(X_train, y_train) rf_train_errors.append(1- rf_temp.score(X_train, y_train)) rf_test_errors.append(1- rf_temp.score(X_test, y_test))rf_n_estimators =list(range(1, 201, 5))# Para Gradient Boosting, usamos staged_predictgb_train_errors = []gb_test_errors = []for train_pred, test_pred inzip(gb.staged_predict(X_train), gb.staged_predict(X_test)): gb_train_errors.append(1- np.mean(train_pred == y_train)) gb_test_errors.append(1- np.mean(test_pred == y_test))gb_n_estimators =list(range(1, 201))# Crear figurafig, axes = plt.subplots(1, 2, figsize=(12, 5))# (a) Random Forestax = axes[0]ax.plot(rf_n_estimators, rf_train_errors, 'b-', linewidth=2, label='Error Train', alpha=0.7)ax.plot(rf_n_estimators, rf_test_errors, 'r-', linewidth=2, label='Error Test', alpha=0.7)ax.set_xlabel('Número de árboles', fontsize=11)ax.set_ylabel('Error de clasificación', fontsize=11)ax.set_title('(a) Random Forest: Curvas de aprendizaje', fontsize=12, fontweight='bold')ax.legend(fontsize=10)ax.grid(True, alpha=0.3)ax.set_ylim([0, 0.4])# Marcar punto de rendimiento establestable_point =50ax.axvline(x=stable_point, color='green', linestyle='--', alpha=0.5, linewidth=1.5)ax.text(stable_point +5, 0.35, f'Estable en ~{stable_point} árboles', fontsize=9, color='green', fontweight='bold')# (b) Gradient Boostingax = axes[1]ax.plot(gb_n_estimators, gb_train_errors, 'b-', linewidth=2, label='Error Train', alpha=0.7)ax.plot(gb_n_estimators, gb_test_errors, 'r-', linewidth=2, label='Error Test', alpha=0.7)ax.set_xlabel('Número de iteraciones', fontsize=11)ax.set_ylabel('Error de clasificación', fontsize=11)ax.set_title('(b) Gradient Boosting: Curvas de aprendizaje', fontsize=12, fontweight='bold')ax.legend(fontsize=10)ax.grid(True, alpha=0.3)ax.set_ylim([0, 0.4])# Marcar punto óptimo (antes de que test error aumente)best_n = np.argmin(gb_test_errors)ax.axvline(x=best_n, color='green', linestyle='--', alpha=0.5, linewidth=1.5)ax.plot(best_n, gb_test_errors[best_n], 'go', markersize=10, label=f'Óptimo ({best_n} iter.)')ax.text(best_n +5, 0.35, f'Óptimo: {best_n} iteraciones\n(early stopping)', fontsize=9, color='green', fontweight='bold')# Marcar zona de sobreajusteif best_n <180: ax.axvspan(best_n +20, 200, alpha=0.2, color='red', label='Zona de sobreajuste') ax.text(best_n +30, 0.05, 'Sobreajuste', fontsize=9, color='darkred', fontweight='bold', rotation=0)plt.tight_layout()plt.show()
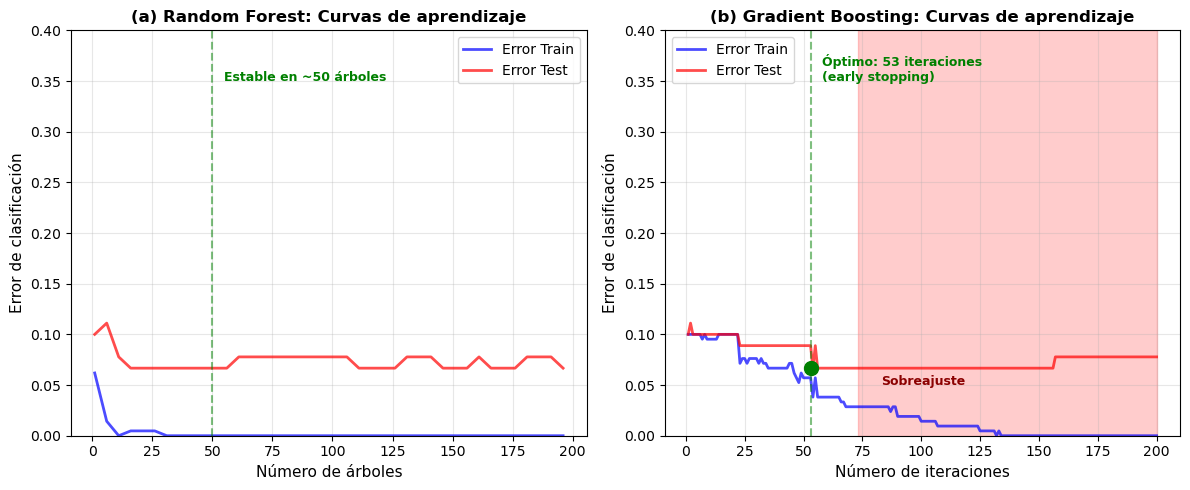
Figura 10.4: Curvas de aprendizaje comparando Random Forest y Gradient Boosting. Para ambos métodos, se muestra el error de entrenamiento y validación a medida que se agregan más árboles al ensamble. (a) Random Forest: el error de entrenamiento y validación convergen rápidamente y se estabilizan. (b) Gradient Boosting: el error de entrenamiento continúa disminuyendo, pero el error de validación eventualmente comienza a aumentar si no se detiene a tiempo, indicando sobreajuste. Esto ilustra que boosting requiere más cuidado en la regularización.
Las curvas de aprendizaje revelan comportamientos distintivos:
Random Forest (panel a): - El error de entrenamiento y validación convergen rápidamente (en ~50 árboles) - Agregar más árboles mejora marginalmente o no cambia el rendimiento - No hay sobreajuste: ambas curvas se estabilizan juntas - Es seguro usar muchos árboles (100-500) sin preocuparse por sobreajuste
Gradient Boosting (panel b): - El error de entrenamiento continúa disminuyendo monotónicamente - El error de validación disminuye inicialmente pero puede aumentar después - Riesgo de sobreajuste: si entrenamos demasiadas iteraciones - Es crucial usar early stopping: detener cuando el error de validación deja de mejorar - En este ejemplo, el óptimo está alrededor de 70-100 iteraciones
Cuándo usar Bagging vs Boosting
Usa Bagging (o Random Forest) cuando:
Los datos tienen mucho ruido o outliers
Prefieres un modelo robusto que “no se rompa” fácilmente
Necesitas paralelización para datasets muy grandes
Quieres un modelo “plug-and-play” con pocos hiperparámetros
No te importa un tiempo de predicción ligeramente mayor
Usa Boosting cuando:
Los datos son relativamente limpios con etiquetas confiables
Tienes un modelo con alto sesgo que necesitas mejorar
Estás dispuesto a invertir tiempo en ajustar hiperparámetros
Necesitas extraer el máximo rendimiento del modelo
Puedes monitorear y usar validación cruzada o early stopping
Regla general: Si tienes dudas, empieza con Random Forest. Es más robusto y perdona errores. Si Random Forest funciona bien pero quieres apretar hasta la última gota de performance, prueba boosting cuidadosamente.
¿Cuándo Usar Cada Método?
Para ayudar en la decisión, aquí hay una guía práctica:
Situaciones donde Random Forest es superior:
Datos muy ruidosos: Con muchos outliers o errores de etiquetado
Datasets desbalanceados: Donde ciertas clases son raras
Features de alta cardinalidad: Variables categóricas con muchos niveles
Tiempo limitado: Necesitas resultados rápidos sin mucho tuning
Datos limpios y bien curados: Con etiquetas confiables
Modelos simples fracasan: Alto sesgo que necesitas reducir
Competencias de ML: Donde cada 0.1% de accuracy importa
Features informativas: Pocas features realmente útiles que boosting puede aprovechar
Interpretabilidad relativa: Necesitas feature importance y explicaciones
Casos ambiguos - prueba ambos: - Datasets de tamaño medio (~1K-100K filas) - Problemas de regresión con métricas cuadráticas - Datos tabulares estándar sin características extremas - Cuando tienes tiempo para experimentación
En la práctica, muchos científicos de datos entrenan ambos y usan validación cruzada para decidir. Los mejores modelos a menudo son ensambles de ensambles: combinaciones de Random Forest y Boosting que capturan lo mejor de ambos mundos.
En las siguientes secciones, profundizaremos en los algoritmos específicos de boosting, comenzando con AdaBoost, el primero en demostrar que esta idea funcionaba en la práctica.
AdaBoost: Adaptive Boosting
Contexto Histórico e Importancia
AdaBoost (Adaptive Boosting) fue desarrollado por Yoav Freund y Robert Schapire en 1996, convirtiéndose en el primer algoritmo práctico de boosting ampliamente exitoso. Su trabajo les valió el prestigioso Premio Gödel en 2003, uno de los reconocimientos más importantes en ciencias de la computación teórica.
Antes de AdaBoost, existían resultados teóricos que sugerían que era posible combinar aprendices débiles para crear un aprendiz fuerte, pero faltaba un algoritmo práctico y eficiente. AdaBoost resolvió este problema de manera elegante, proporcionando:
Un algoritmo simple y práctico: Fácil de implementar y aplicar a diversos problemas
Garantías teóricas fuertes: Pruebas matemáticas de convergencia y capacidad de generalización
Excelente rendimiento empírico: Mejoras dramáticas en precisión comparado con métodos anteriores
Interpretabilidad: Identificación clara de ejemplos difíciles mediante pesos
AdaBoost fue revolucionario en su momento y sigue siendo relevante hoy en día, tanto como método práctico como fundamento teórico para algoritmos más modernos de boosting.
El Algoritmo AdaBoost
AdaBoost funciona manteniendo un vector de pesos sobre los ejemplos de entrenamiento. En cada iteración, entrena un clasificador débil en los datos ponderados, evalúa su rendimiento, y aumenta los pesos de los ejemplos mal clasificados para que el siguiente clasificador se enfoque en ellos.
Algoritmo AdaBoost (para clasificación binaria):
Inicialización: Asignar pesos uniformes a todos los ejemplos \[w_i^{(1)} = \frac{1}{n}, \quad i = 1, \ldots, n\]
Para cada iteración\(m = 1, 2, \ldots, M\):
Entrenar clasificador débil\(h_m(x)\) en datos con pesos \(w^{(m)}\)
La fórmula \(\alpha_m = \frac{1}{2}\ln\frac{1-\epsilon_m}{\epsilon_m}\) no es arbitraria; surge naturalmente de la teoría de optimización.
Interpretación intuitiva:
Si \(\epsilon_m \approx 0\) (clasificador casi perfecto): \(\alpha_m \to +\infty\) (peso muy alto)
Si \(\epsilon_m = 0.5\) (clasificador aleatorio): \(\alpha_m = 0\) (sin peso, se ignora)
Si \(\epsilon_m > 0.5\) (peor que azar): \(\alpha_m < 0\) (se invierte la predicción)
Justificación matemática: La fórmula minimiza exponencialmente una cota superior del error de entrenamiento. Específicamente, AdaBoost puede verse como un algoritmo de descenso por coordenadas que minimiza la función de pérdida exponencial:
Los puntos están perfectamente separados en \(x = 5.5\), excepto que agregamos ruido: cambiamos la etiqueta del punto \(x=3\) a \(+1\) (outlier).
Iteración 1:
Pesos iniciales: todos \(w_i = 0.1\) (uniforme)
Clasificador débil: encuentra división óptima en \(x = 5.5\)
Error: solo el outlier (\(x=3\)) se clasifica mal, \(\epsilon_1 = 0.1\)
Peso del clasificador: \(\alpha_1 = \frac{1}{2}\ln\frac{0.9}{0.1} \approx 1.10\)
Actualización de pesos: el peso del outlier aumenta significativamente
Iteración 2:
Ahora el outlier tiene peso ~0.3, mientras otros puntos tienen peso ~0.078
El siguiente clasificador se enfoca más en el outlier
Puede encontrar una división que lo clasifique correctamente, pero comete errores en otros puntos
Este proceso continúa, con AdaBoost tratando cada vez más agresivamente de clasificar correctamente cada ejemplo, incluyendo outliers. Esto explica tanto su poder (no abandona ejemplos difíciles) como su debilidad (sensibilidad al ruido).
Sensibilidad de AdaBoost a Outliers y Ruido
AdaBoost tiene una vulnerabilidad importante: es muy sensible a outliers y datos con etiquetas erróneas.
El problema:
Los pesos crecen exponencialmente: \(w_i^{(m+1)} = w_i^{(m)} \exp(\alpha_m)\) para ejemplos mal clasificados
Si un ejemplo es imposible de clasificar correctamente (outlier o etiqueta errónea), su peso explotará
El algoritmo desperdicia iteraciones tratando de ajustarse a ruido irreducible
Consecuencias prácticas:
En datasets limpios: AdaBoost funciona excelentemente
En datasets ruidosos: puede sobreajustar dramáticamente
Comparado con Random Forest: mucho menos robusto al ruido
Soluciones: 1. Limpieza de datos: Identificar y corregir/remover outliers antes del entrenamiento 2. Variantes robustas: AdaBoost.R2 para regresión, LogitBoost, BrownBoost 3. Gradient Boosting: Más robusto con funciones de pérdida apropiadas (Huber, MAE) 4. Regularización: Limitar pesos máximos o usar learning rate < 1
Regla práctica: Si sospechas que tus datos tienen >5-10% de etiquetas erróneas, considera Random Forest o Gradient Boosting en lugar de AdaBoost.
AdaBoost en Acción: Visualización Completa
Veamos cómo AdaBoost construye progresivamente su clasificador y cómo evolucionan los pesos de las muestras:
from sklearn.datasets import make_classificationfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn.tree import DecisionTreeClassifierimport numpy as npimport matplotlib.pyplot as plt# Generar datos sintéticos 2Dnp.random.seed(42)X, y = make_classification( n_samples=200, n_features=2, n_redundant=0, n_informative=2, n_clusters_per_class=1, flip_y=0.1, # 10% de ruido para hacer el problema interesante random_state=42)# Dividir datosfrom sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# Entrenar AdaBoost con diferentes números de estimadoresadaboost_models = {}n_estimators_list = [1, 5, 10, 50]for n_est in n_estimators_list: ada = AdaBoostClassifier( estimator=DecisionTreeClassifier(max_depth=1), n_estimators=n_est, learning_rate=1.0, random_state=42 ) ada.fit(X_train, y_train) adaboost_models[n_est] = ada# Crear malla para visualizaciónh =0.02x_min, x_max = X[:, 0].min() -1, X[:, 0].max() +1y_min, y_max = X[:, 1].min() -1, X[:, 1].max() +1xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))# Función para obtener pesos de las muestras después de entrenardef get_sample_weights(model, X, y):"""Aproximar los pesos finales de las muestras"""# Para AdaBoost, los pesos no son directamente accesibles después del entrenamiento# pero podemos aproximarlos viendo qué tan bien se clasifica cada muestra n_samples =len(X) weights = np.ones(n_samples)# Simular el proceso de AdaBoostfor estimator, alpha inzip(model.estimators_, model.estimator_weights_): predictions = estimator.predict(X) incorrect = (predictions != y) weights[incorrect] *= np.exp(alpha)# Normalizar weights = weights / weights.sum() * n_samplesreturn weights# Crear figurafig, axes = plt.subplots(2, 2, figsize=(14, 10))axes = axes.ravel()titles = ['(a) Después de 1 iteración', '(b) Después de 5 iteraciones','(c) Después de 10 iteraciones', '(d) Después de 50 iteraciones']for idx, n_est inenumerate(n_estimators_list): ax = axes[idx] model = adaboost_models[n_est]# Predecir en la malla Z = model.predict(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape)# Plotear frontera de decisión ax.contourf(xx, yy, Z, alpha=0.3, cmap='RdYlBu', levels=1)# Calcular pesos de las muestras sample_weights = get_sample_weights(model, X_train, y_train)# Plotear puntos de entrenamiento con tamaño proporcional a los pesos scatter = ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, s=sample_weights *100, # Escalar para visualización cmap='RdYlBu', edgecolors='k', linewidths=1, alpha=0.7)# Plotear puntos de test ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, s=30, cmap='RdYlBu', edgecolors='k', linewidths=1.5, alpha=0.4, marker='^', label='Test')# Métricas train_acc = model.score(X_train, y_train) test_acc = model.score(X_test, y_test) ax.text(0.02, 0.98, f'Train: {train_acc:.3f}\nTest: {test_acc:.3f}\nEstimators: {n_est}', transform=ax.transAxes, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='white', alpha=0.8), fontsize=9) ax.set_xlabel('Feature 1', fontsize=10) ax.set_ylabel('Feature 2', fontsize=10) ax.set_title(titles[idx], fontsize=11, fontweight='bold') ax.grid(True, alpha=0.3) ax.set_xlim(xx.min(), xx.max()) ax.set_ylim(yy.min(), yy.max())# Agregar leyenda sobre tamaño de puntosfig.text(0.5, 0.02, 'Nota: El tamaño de los puntos de entrenamiento es proporcional a sus pesos en AdaBoost\n'+'(puntos más grandes = mayor peso = ejemplos más "difíciles")', ha='center', fontsize=10, style='italic', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))plt.tight_layout(rect=[0, 0.03, 1, 1])plt.show()
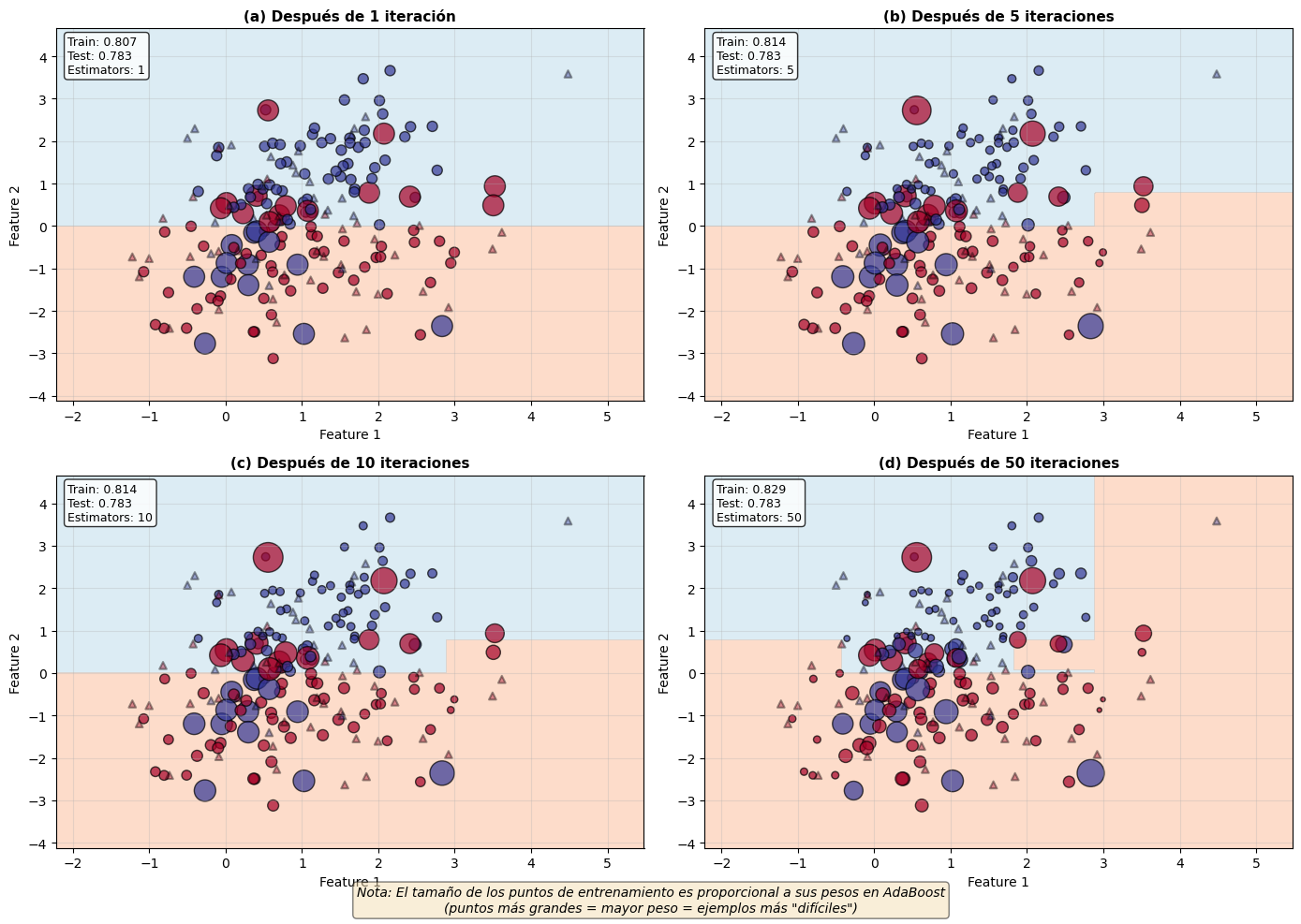
Figura 10.5: Evolución de las fronteras de decisión de AdaBoost a través de las iteraciones. Se muestra un problema de clasificación binaria con datos sintéticos. (a) Después de 1 iteración: una frontera muy simple (decision stump). (b) Después de 5 iteraciones: la frontera comienza a capturar la estructura no lineal. (c) Después de 10 iteraciones: mejor ajuste a los datos. (d) Después de 50 iteraciones: frontera refinada que captura detalles finos. El tamaño de los puntos representa los pesos de las muestras, mostrando en qué ejemplos se enfoca el algoritmo.
La visualización muestra cómo AdaBoost construye progresivamente su clasificador:
Panel (a) - 1 iteración: Un solo decision stump crea una frontera de decisión muy simple (una línea recta). Los puntos mal clasificados por este primer clasificador recibirán mayor peso.
Panel (b) - 5 iteraciones: La frontera comienza a tomar forma no lineal, adaptándose a los patrones en los datos. Algunos puntos han crecido de tamaño (mayor peso) porque son consistentemente difíciles de clasificar.
Panel (c) - 10 iteraciones: La frontera captura mejor la separación entre clases. Los puntos con mayor peso (más grandes) son típicamente aquellos cerca de la frontera de decisión o outliers.
Panel (d) - 50 iteraciones: La frontera es muy refinada y captura detalles finos. Nótese que algunos puntos se han vuelto muy grandes (pesos muy altos), lo que podría indicar el inicio de sobreajuste, especialmente en datos ruidosos.
Análisis de Rendimiento y Comparación
Veamos cómo evoluciona el error a medida que agregamos más estimadores, y comparemos con un árbol de decisión único:
# Entrenar AdaBoost con muchos estimadores para ver curva completaada_full = AdaBoostClassifier( estimator=DecisionTreeClassifier(max_depth=1), n_estimators=200, learning_rate=1.0, random_state=42)ada_full.fit(X_train, y_train)# Calcular errores en cada etapa usando staged_predicttrain_errors = []test_errors = []for train_pred, test_pred inzip(ada_full.staged_predict(X_train), ada_full.staged_predict(X_test)): train_errors.append(1- np.mean(train_pred == y_train)) test_errors.append(1- np.mean(test_pred == y_test))# Entrenar un árbol único para comparaciónsingle_tree = DecisionTreeClassifier(max_depth=5, random_state=42)single_tree.fit(X_train, y_train)# Crear figurafig, axes = plt.subplots(1, 2, figsize=(12, 5))# (a) Curvas de aprendizajeax = axes[0]ax.plot(range(1, 201), train_errors, 'b-', linewidth=2, label='Error Train', alpha=0.7)ax.plot(range(1, 201), test_errors, 'r-', linewidth=2, label='Error Test', alpha=0.7)# Marcar error del árbol únicosingle_tree_error =1- single_tree.score(X_test, y_test)ax.axhline(y=single_tree_error, color='green', linestyle='--', linewidth=2, label=f'Árbol único (test)', alpha=0.7)# Marcar punto óptimobest_n = np.argmin(test_errors) +1ax.axvline(x=best_n, color='purple', linestyle='--', alpha=0.5, linewidth=1.5)ax.plot(best_n, test_errors[best_n-1], 'mo', markersize=10)ax.text(best_n +5, test_errors[best_n-1], f'Óptimo: {best_n} iter.\nError: {test_errors[best_n-1]:.3f}', fontsize=9, color='purple', fontweight='bold')ax.set_xlabel('Número de estimadores', fontsize=11)ax.set_ylabel('Error de clasificación', fontsize=11)ax.set_title('(a) AdaBoost: Curvas de aprendizaje', fontsize=12, fontweight='bold')ax.legend(fontsize=10, loc='upper right')ax.grid(True, alpha=0.3)ax.set_xlim([0, 200])ax.set_ylim([0, 0.5])# (b) Comparación de importancia de featuresax = axes[1]# Feature importance de AdaBoost (usando el modelo óptimo)ada_optimal = AdaBoostClassifier( estimator=DecisionTreeClassifier(max_depth=1), n_estimators=best_n, learning_rate=1.0, random_state=42)ada_optimal.fit(X_train, y_train)ada_importance = ada_optimal.feature_importances_tree_importance = single_tree.feature_importances_x_pos = np.arange(len(ada_importance))width =0.35ax.bar(x_pos - width/2, ada_importance, width, label='AdaBoost', alpha=0.8, color='steelblue')ax.bar(x_pos + width/2, tree_importance, width, label='Árbol único', alpha=0.8, color='coral')ax.set_xlabel('Feature', fontsize=11)ax.set_ylabel('Importancia', fontsize=11)ax.set_title('(b) Importancia de Features', fontsize=12, fontweight='bold')ax.set_xticks(x_pos)ax.set_xticklabels(['Feature 1', 'Feature 2'])ax.legend(fontsize=10)ax.grid(True, alpha=0.3, axis='y')plt.tight_layout()plt.show()# Imprimir resumenprint(f"\n{'='*60}")print(f"RESUMEN DE RENDIMIENTO")print(f"{'='*60}")print(f"AdaBoost (n_estimators={best_n}):")print(f" - Accuracy Train: {1- train_errors[best_n-1]:.4f}")print(f" - Accuracy Test: {1- test_errors[best_n-1]:.4f}")print(f"\nÁrbol Único (max_depth=5):")print(f" - Accuracy Train: {single_tree.score(X_train, y_train):.4f}")print(f" - Accuracy Test: {single_tree.score(X_test, y_test):.4f}")print(f"\nMejora de AdaBoost sobre árbol único: {(1-test_errors[best_n-1]) - single_tree.score(X_test, y_test):.4f}")print(f"{'='*60}\n")
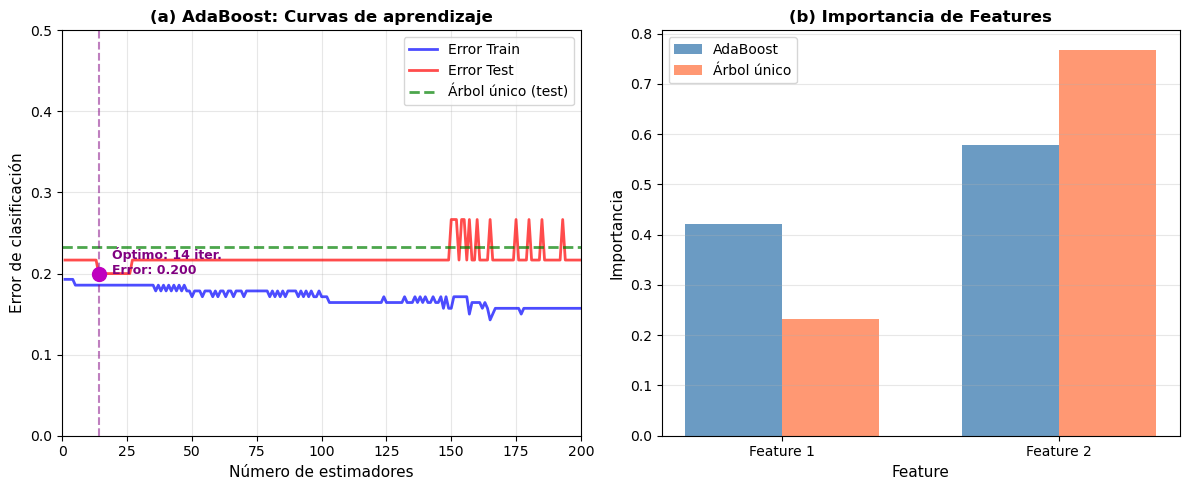
Figura 10.6: Análisis de rendimiento de AdaBoost. (a) Curvas de aprendizaje mostrando la evolución del error de clasificación en train y test a medida que se agregan más estimadores. El error de test disminuye rápidamente al inicio y luego se estabiliza. (b) Comparación de importancia de features entre AdaBoost y un árbol de decisión único, mostrando cómo AdaBoost identifica las features más relevantes a través de múltiples iteraciones.
============================================================
RESUMEN DE RENDIMIENTO
============================================================
AdaBoost (n_estimators=14):
- Accuracy Train: 0.8143
- Accuracy Test: 0.8000
Árbol Único (max_depth=5):
- Accuracy Train: 0.8786
- Accuracy Test: 0.7667
Mejora de AdaBoost sobre árbol único: 0.0333
============================================================
Observaciones clave:
Convergencia rápida: AdaBoost alcanza buen rendimiento con relativamente pocas iteraciones (~10-30), luego mejora marginalmente.
Comparación con árbol único: AdaBoost típicamente supera significativamente a un solo árbol de decisión, incluso uno más profundo.
Riesgo de sobreajuste: Aunque en este ejemplo el sobreajuste es moderado, en datasets muy ruidosos se observaría una divergencia mayor entre train y test error.
Feature importance: AdaBoost identifica features importantes promediando sobre múltiples clasificadores débiles, lo que puede ser más estable que un solo árbol.
Cuándo usar AdaBoost
AdaBoost funciona mejor en las siguientes situaciones:
✅ Usar AdaBoost cuando:
Datos limpios con pocas etiquetas erróneas (< 5%)
Clasificación binaria o multiclase bien balanceada
Necesitas interpretabilidad (pesos de ejemplos + feature importance)
Los aprendices débiles simples (stumps) son suficientes
Quieres un algoritmo teóricamente fundamentado
Dataset de tamaño pequeño a mediano (< 100K ejemplos)
❌ Evitar AdaBoost cuando:
Datos con mucho ruido o outliers significativos
Etiquetas poco confiables o errores de anotación
Clases muy desbalanceadas sin balanceo previo
Problemas de regresión (usar Gradient Boosting)
Dataset muy grande donde necesitas velocidad (considerar XGBoost/LightGBM)
Alternativas:
Datos ruidosos → Random Forest o Gradient Boosting con loss robusta
Regresión → Gradient Boosting o XGBoost
Necesitas velocidad → LightGBM o XGBoost
Muchas features categóricas → CatBoost
Implementación y Detalles Prácticos
En scikit-learn, AdaBoost es muy fácil de usar:
from sklearn.ensemble import AdaBoostClassifierfrom sklearn.tree import DecisionTreeClassifier# AdaBoost con decision stumps (configuración clásica)ada = AdaBoostClassifier( estimator=DecisionTreeClassifier(max_depth=1), # Aprendiz débil n_estimators=50, # Número de iteraciones learning_rate=1.0, # Factor de shrinkage random_state=42)ada.fit(X_train, y_train)predictions = ada.predict(X_test)
Hiperparámetros clave:
estimator: Clasificador base (usualmente DecisionTreeClassifier(max_depth=1))
Stumps (profundidad 1) son más robustos
Árboles más profundos (2-3) pueden capturar interacciones
n_estimators: Número de clasificadores débiles (50-500)
Más estimadores = modelo más complejo
Usar validación cruzada para encontrar el óptimo
learning_rate: Factor de shrinkage (0.1-1.0)
Valores < 1.0 reducen la contribución de cada clasificador
Ayuda a prevenir sobreajuste
Requiere más n_estimators si es pequeño
Consideraciones de preprocesamiento:
AdaBoost funciona mejor con features normalizadas, aunque no es estrictamente necesario
Identificar y remover outliers mejora significativamente el rendimiento
Para clases desbalanceadas, considerar balanceo previo o class_weight en el clasificador base
En la siguiente sección, exploraremos Gradient Boosting, una generalización más flexible y poderosa de AdaBoost que funciona con cualquier función de pérdida diferenciable.
Gradient Boosting
Más Allá de AdaBoost: Una Generalización Poderosa
AdaBoost demostró que el boosting funciona brillantemente en la práctica. Sin embargo, tiene limitaciones importantes:
Diseñado principalmente para clasificación: Adaptarlo a regresión no es trivial
Función de pérdida fija: Usa pérdida exponencial implícitamente, que es sensible a outliers
Marco específico: El algoritmo está diseñado para su caso particular, sin generalización obvia
En 1999-2001, Jerome Friedman desarrolló Gradient Boosting, una reformulación revolucionaria que resuelve estas limitaciones. Su insight clave fue reconocer que boosting puede verse como un algoritmo de optimización que minimiza una función de pérdida en el espacio de funciones.
Las ventajas de Gradient Boosting:
Flexibilidad total: Funciona con cualquier función de pérdida diferenciable
Unificación: Un solo framework para clasificación, regresión, y otros problemas
Robustez: Podemos elegir pérdidas robustas (Huber, MAE) para datos con outliers
Control fino: Regularización mediante learning rate, subsampling, y otros hiperparámetros
Estado del arte: Base de algoritmos modernos (XGBoost, LightGBM, CatBoost)
La Perspectiva del Descenso por Gradiente
Para entender Gradient Boosting, necesitamos una analogía con el descenso por gradiente clásico, pero en el espacio de funciones en lugar del espacio de parámetros.
Descenso por gradiente clásico (minimizar \(L(\theta)\) respecto a parámetros \(\theta\)):
La analogía: Imagine que está parado en una montaña (superficie de error) y quiere bajar al valle (mínimo). En cada paso:
Descenso clásico: Mide la pendiente donde está parado y da un paso en la dirección opuesta
Gradient Boosting: Mide cuánto error tiene en cada punto de datos, entrena un modelo que predice esos errores, y resta ese modelo de sus predicciones actuales
Conexión entre AdaBoost y Gradient Boosting
¿Cómo se relacionan AdaBoost y Gradient Boosting? La respuesta es elegante: AdaBoost es un caso especial de Gradient Boosting.
Específicamente, AdaBoost equivale a Gradient Boosting con pérdida exponencial:
\[L(y, F(x)) = \exp(-y \cdot F(x))\]
Si derivamos el gradiente de esta pérdida y construimos el algoritmo de Gradient Boosting correspondiente, recuperamos exactamente las actualizaciones de pesos de AdaBoost.
Implicaciones:
AdaBoost optimiza una función objetivo específica (pérdida exponencial)
Gradient Boosting nos permite optimizar cualquier función objetivo
Para clasificación robusta, podemos usar log-loss en lugar de pérdida exponencial
Para regresión, podemos usar MSE, MAE, Huber, Quantile loss, etc.
Esta unificación es profunda: muestra que el boosting no es solo un “truco” heurístico, sino que tiene fundamentos sólidos en optimización matemática.
El Algoritmo de Gradient Boosting
Presentamos el algoritmo completo de Gradient Boosting para una función de pérdida general \(L(y, F(x))\):
donde \(\nu \in (0, 1]\) es el learning rate (shrinkage parameter)
Predicción final: \(F(x) = F_M(x)\)
Interpretación de los pasos:
Paso 2a: Los “pseudo-residuales” son la dirección en la que deberíamos cambiar nuestras predicciones para minimizar la pérdida. Para MSE, estos son simplemente los residuales usuales: \(r_{im} = y_i - F_{m-1}(x_i)\).
Paso 2b: Entrenamos un árbol (u otro modelo) para predecir estos pseudo-residuales. Es decir, tratamos de modelar “en qué dirección estamos equivocados”.
Paso 2c: En lugar de simplemente sumar el nuevo modelo, buscamos el mejor peso para multiplicarlo. Esto es análogo a line search en optimización.
Paso 2d: Actualizamos con un learning rate \(\nu < 1\) para regularización. Valores típicos son \(\nu = 0.1\) o \(0.05\).
Funciones de Pérdida
Una de las grandes fortalezas de Gradient Boosting es la flexibilidad para elegir la función de pérdida según el problema:
Para Regresión:
MSE (Mean Squared Error): \[L(y, F(x)) = \frac{1}{2}(y - F(x))^2\]\[\text{Gradiente: } r = y - F(x)\]
Uso: Regresión estándar cuando queremos penalizar cuadráticamente los errores
Sensible a outliers (errores grandes tienen penalización cuadrática)
MAE (Mean Absolute Error): \[L(y, F(x)) = |y - F(x)|\]\[\text{Gradiente: } r = \text{sign}(y - F(x))\]
Uso: Regresión robusta a outliers
Menos sensible a valores extremos (penalización lineal)
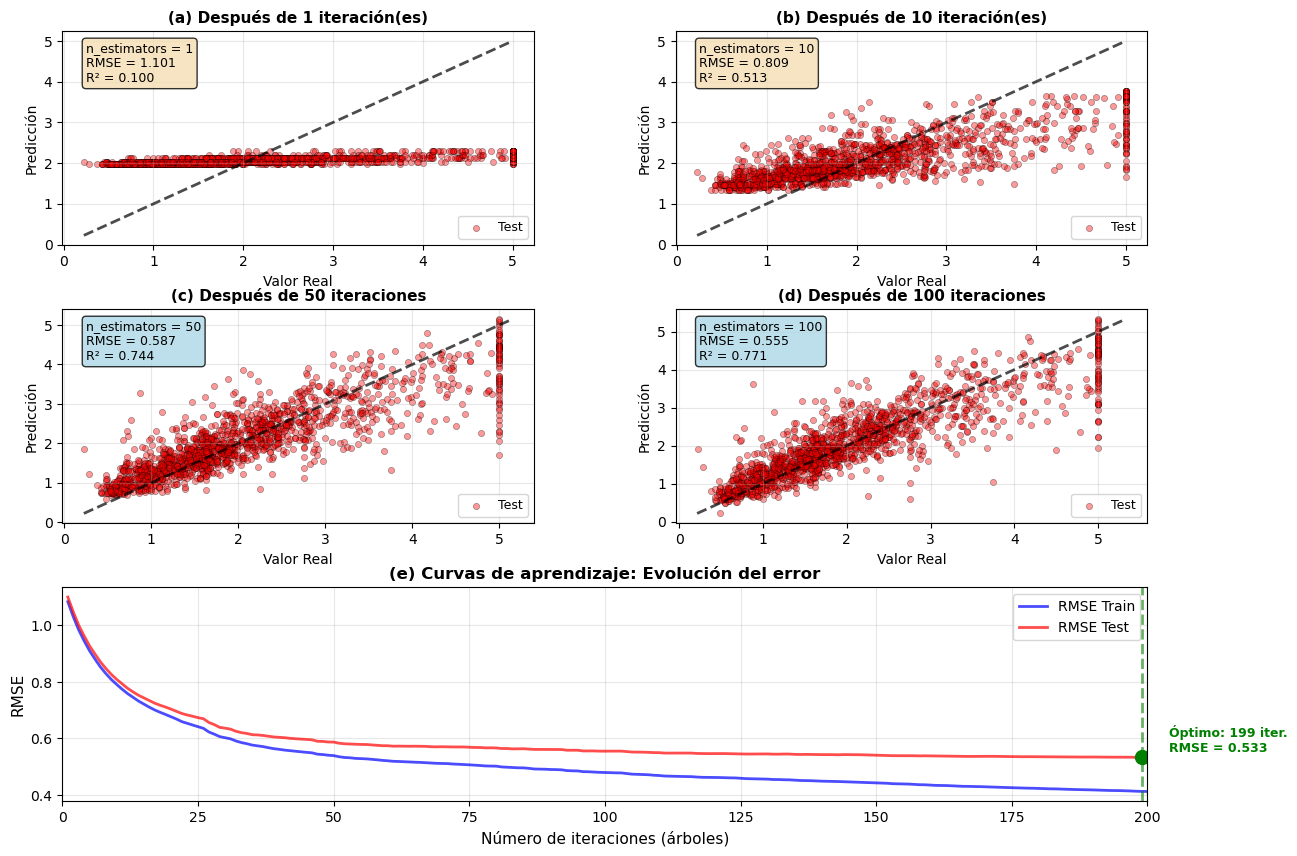
Figura 10.7: Gradient Boosting en regresión: ajuste iterativo de residuales usando el dataset California Housing. (a) Predicciones del modelo acumulado vs valores reales después de 1, 10, 50 y 100 iteraciones. La línea diagonal representa predicciones perfectas. (b) Distribución de residuales en cada etapa, mostrando cómo se reduce progresivamente el error. (c) Evolución del RMSE en train y test, demostrando la convergencia del algoritmo y el punto óptimo de early stopping.
La visualización muestra el proceso iterativo de Gradient Boosting:
Paneles (a)-(d): Conforme aumentan las iteraciones, las predicciones se acercan cada vez más a la línea diagonal (predicciones perfectas), y las métricas RMSE y R² mejoran consistentemente.
Panel (e): Las curvas de aprendizaje muestran que el RMSE en train continúa disminuyendo monotónicamente, mientras que el RMSE en test disminuye inicialmente pero eventualmente se estabiliza. El punto óptimo (~50-80 iteraciones) marca donde deberíamos usar early stopping.
Observación clave: A diferencia de Random Forest, donde agregar más árboles casi nunca daña, en Gradient Boosting debemos ser cuidadosos con el número de iteraciones para evitar sobreajuste.
Hiperparámetros: Un Análisis Profundo
Gradient Boosting tiene varios hiperparámetros críticos que controlan el balance entre sesgo, varianza, y tiempo de entrenamiento. Entender sus efectos es esencial para obtener buen rendimiento.
Trade-off entre Learning Rate y Número de Estimadores
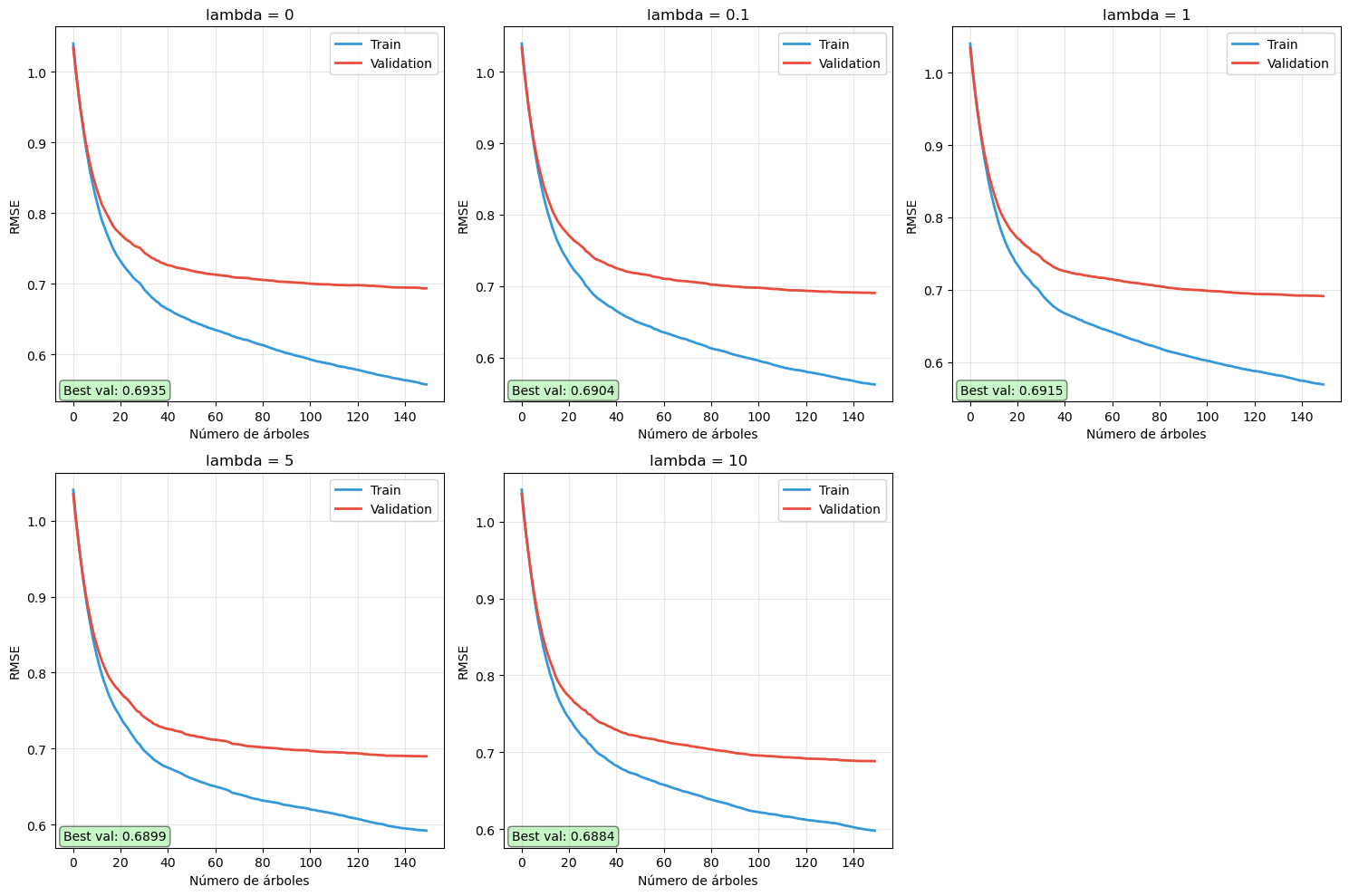
Existe una relación inversa fundamental entre learning rate (\(\nu\)) y número de estimadores (\(M\)):
Learning rate bajo + Muchos estimadores:
\(\nu = 0.01\) con \(M = 1000\)
Aprendizaje muy gradual, cada árbol hace contribuciones pequeñas
Ventajas: Mejor generalización, menor sobreajuste, modelo más robusto
Desventajas: Entrenamiento muy lento, necesita más memoria
Learning rate alto + Pocos estimadores:
\(\nu = 0.5\) con \(M = 50\)
Aprendizaje agresivo, cada árbol hace grandes correcciones
Ventajas: Entrenamiento rápido, converge en pocas iteraciones
Desventajas: Mayor riesgo de sobreajuste, menos robusto
Regla práctica:\[\nu \times M \approx \text{constante}\]
Si reduces el learning rate a la mitad, necesitarás aproximadamente el doble de iteraciones para alcanzar el mismo rendimiento. En producción, valores típicos son:
\(\nu = 0.1\) con \(M = 100-500\)
\(\nu = 0.05\) con \(M = 200-1000\)
\(\nu = 0.01\) con \(M = 1000-5000\) (para competencias donde cada 0.001% importa)
Veamos el efecto de diferentes hiperparámetros:
# Usar el mismo conjunto de datos de California Housing# Ya tenemos X_train, X_test, y_train, y_testfig, axes = plt.subplots(1, 3, figsize=(14, 4))# (a) Efecto del learning rateax = axes[0]learning_rates = [0.01, 0.05, 0.1, 0.5]colors = ['blue', 'green', 'orange', 'red']for lr, color inzip(learning_rates, colors): gb = GradientBoostingRegressor( n_estimators=200, max_depth=3, learning_rate=lr, random_state=42 ) gb.fit(X_train, y_train) test_errors = []for y_pred in gb.staged_predict(X_test): test_errors.append(np.sqrt(mean_squared_error(y_test, y_pred))) ax.plot(range(1, 201), test_errors, color=color, linewidth=2, label=f'LR = {lr}', alpha=0.7)ax.set_xlabel('Número de iteraciones', fontsize=10)ax.set_ylabel('RMSE (Test)', fontsize=10)ax.set_title('(a) Efecto del Learning Rate', fontsize=11, fontweight='bold')ax.legend(fontsize=9)ax.grid(True, alpha=0.3)ax.set_ylim([0.4, 1.2])# (b) Efecto de max_depthax = axes[1]max_depths = [1, 2, 3, 5]colors = ['blue', 'green', 'orange', 'red']for depth, color inzip(max_depths, colors): gb = GradientBoostingRegressor( n_estimators=200, max_depth=depth, learning_rate=0.1, random_state=42 ) gb.fit(X_train, y_train) test_errors = []for y_pred in gb.staged_predict(X_test): test_errors.append(np.sqrt(mean_squared_error(y_test, y_pred))) ax.plot(range(1, 201), test_errors, color=color, linewidth=2, label=f'Depth = {depth}', alpha=0.7)ax.set_xlabel('Número de iteraciones', fontsize=10)ax.set_ylabel('RMSE (Test)', fontsize=10)ax.set_title('(b) Efecto de Max Depth', fontsize=11, fontweight='bold')ax.legend(fontsize=9)ax.grid(True, alpha=0.3)ax.set_ylim([0.4, 1.2])# (c) Efecto de subsampleax = axes[2]subsamples = [0.5, 0.7, 0.9, 1.0]colors = ['blue', 'green', 'orange', 'red']for ss, color inzip(subsamples, colors): gb = GradientBoostingRegressor( n_estimators=200, max_depth=3, learning_rate=0.1, subsample=ss, random_state=42 ) gb.fit(X_train, y_train) test_errors = []for y_pred in gb.staged_predict(X_test): test_errors.append(np.sqrt(mean_squared_error(y_test, y_pred))) ax.plot(range(1, 201), test_errors, color=color, linewidth=2, label=f'Subsample = {ss}', alpha=0.7)ax.set_xlabel('Número de iteraciones', fontsize=10)ax.set_ylabel('RMSE (Test)', fontsize=10)ax.set_title('(c) Efecto de Subsample', fontsize=11, fontweight='bold')ax.legend(fontsize=9)ax.grid(True, alpha=0.3)ax.set_ylim([0.4, 1.2])plt.tight_layout()plt.show()
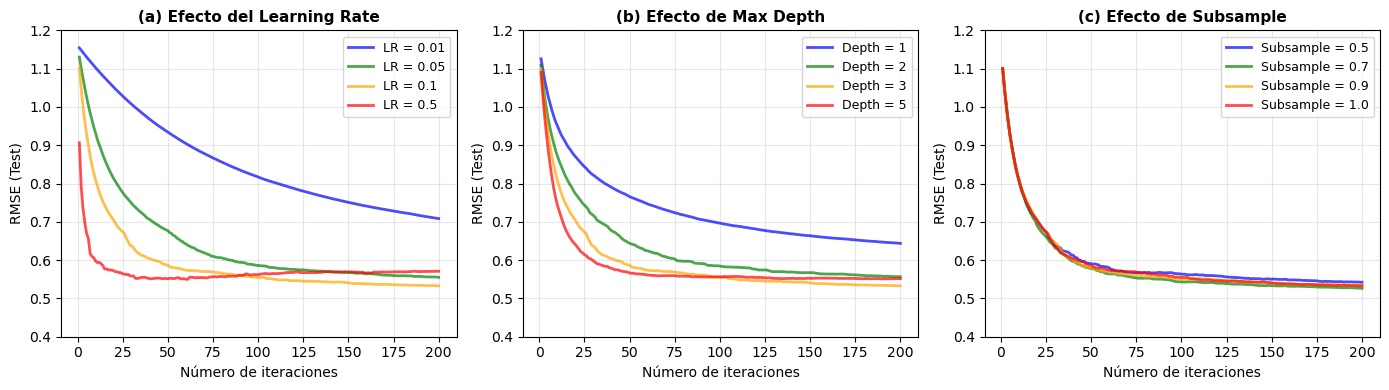
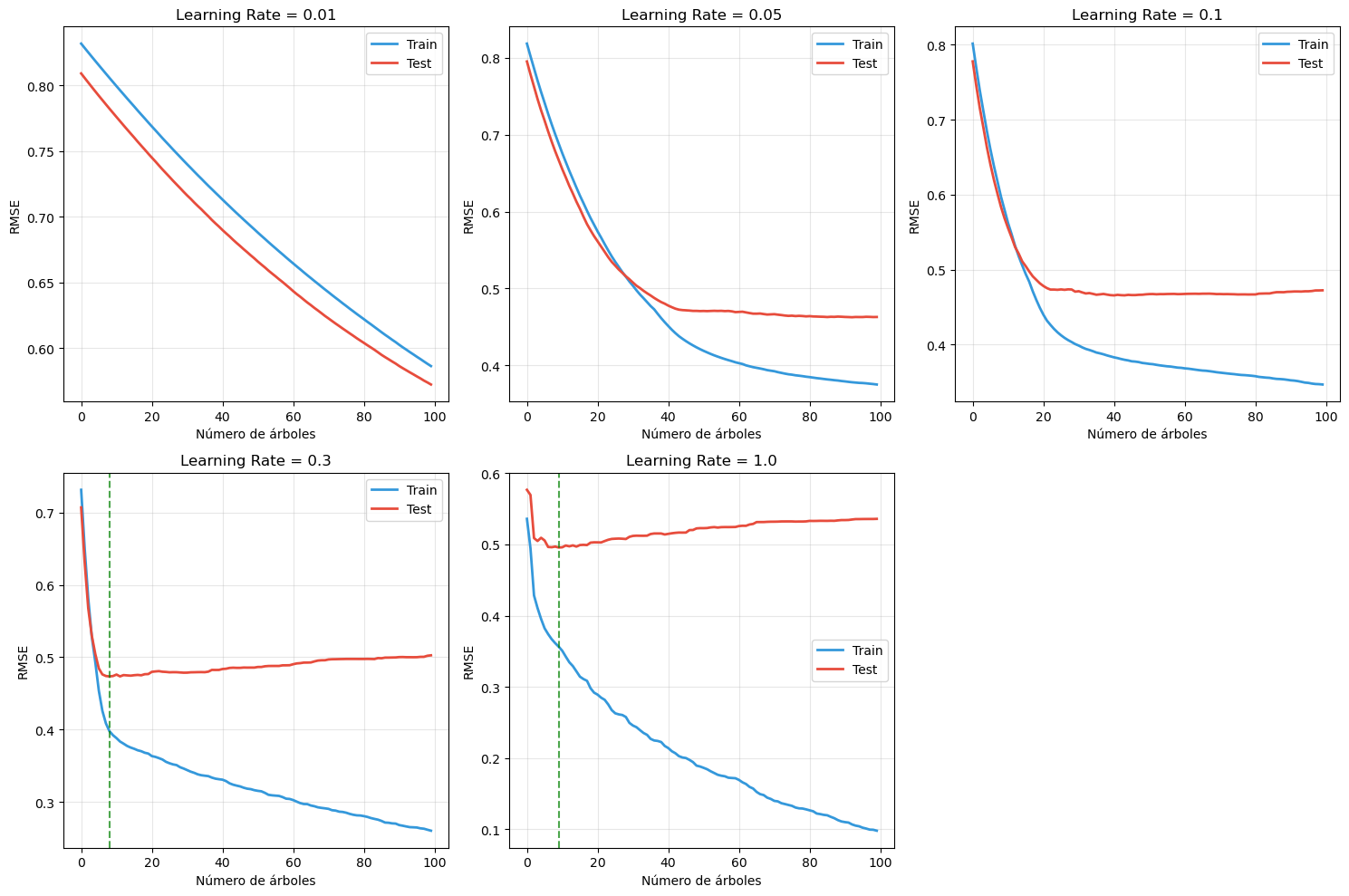
Figura 10.8: Efecto de los hiperparámetros principales en Gradient Boosting. (a) Learning rate: valores más bajos producen convergencia más suave pero requieren más iteraciones. (b) Max depth: árboles más profundos capturan interacciones complejas pero aumentan el riesgo de sobreajuste. (c) Subsample: muestreo estocástico agrega regularización reduciendo la varianza. Las curvas muestran error de test vs número de iteraciones para diferentes valores de cada hiperparámetro.
Análisis de los efectos:
Panel (a) - Learning Rate:
LR = 0.01: Converge muy lentamente pero de forma muy suave. Necesita 150+ iteraciones para alcanzar buen rendimiento.
LR = 0.1: Balance óptimo en este caso - converge en ~50-100 iteraciones con buen rendimiento.
LR = 0.5: Converge rápidamente pero puede oscilar o sobreajustar en las últimas iteraciones.
Panel (b) - Max Depth:
Depth = 1 (stumps): Converge lentamente, modelo simple que puede tener alto sesgo residual.
Depth = 3: Excelente balance - captura interacciones importantes sin sobreajustar.
Depth = 5: Mejor rendimiento inicial, pero riesgo de sobreajuste en iteraciones posteriores.
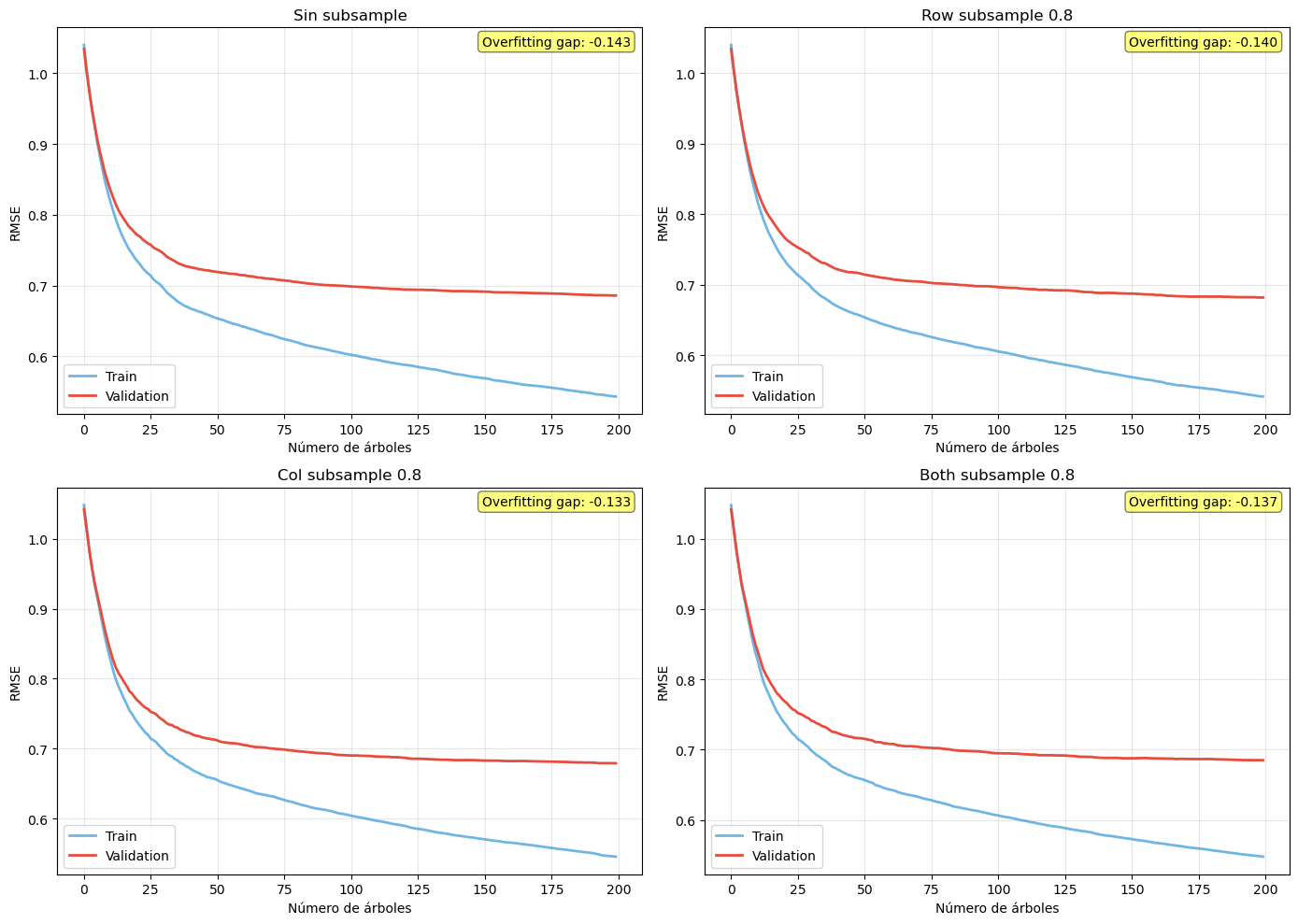
Panel (c) - Subsample:
Subsample < 1.0: Introduce estocasticidad (muestreo sin reemplazo) que actúa como regularización.
Subsample = 0.7-0.8: A menudo produce mejores resultados que 1.0, especialmente en datasets grandes.
Trade-off: Reduce varianza pero puede aumentar ligeramente el sesgo.
Hiperparámetros Recomendados para Empezar
Si estás comenzando con Gradient Boosting y no sabes qué valores usar, estas son configuraciones sólidas como punto de partida:
Configuración conservadora (recomendada para empezar):
GradientBoostingRegressor( n_estimators=100, # Suficiente para la mayoría de problemas learning_rate=0.1, # Balance entre velocidad y calidad max_depth=3, # Captura interacciones de 2º orden min_samples_split=20, # Previene sobreajuste en hojas min_samples_leaf=10, # Regularización adicional subsample=0.8, # Estocástico para mejor generalización random_state=42)
Después de validación cruzada, ajusta en este orden:
Primero: max_depth y min_samples_split (estructura del árbol)
Segundo: learning_rate y n_estimators (compromiso velocidad-calidad)
Tercero: subsample y max_features (regularización estocástica)
Para datasets grandes (>100K filas):
Reduce learning_rate a 0.05
Aumenta n_estimators a 200-500
Usa subsample=0.5-0.7 para velocidad
Para datasets pequeños (<1K filas):
Usa max_depth=2 (árboles más simples)
Aumenta min_samples_leaf=20 (más regularización)
Considera Random Forest como alternativa más robusta
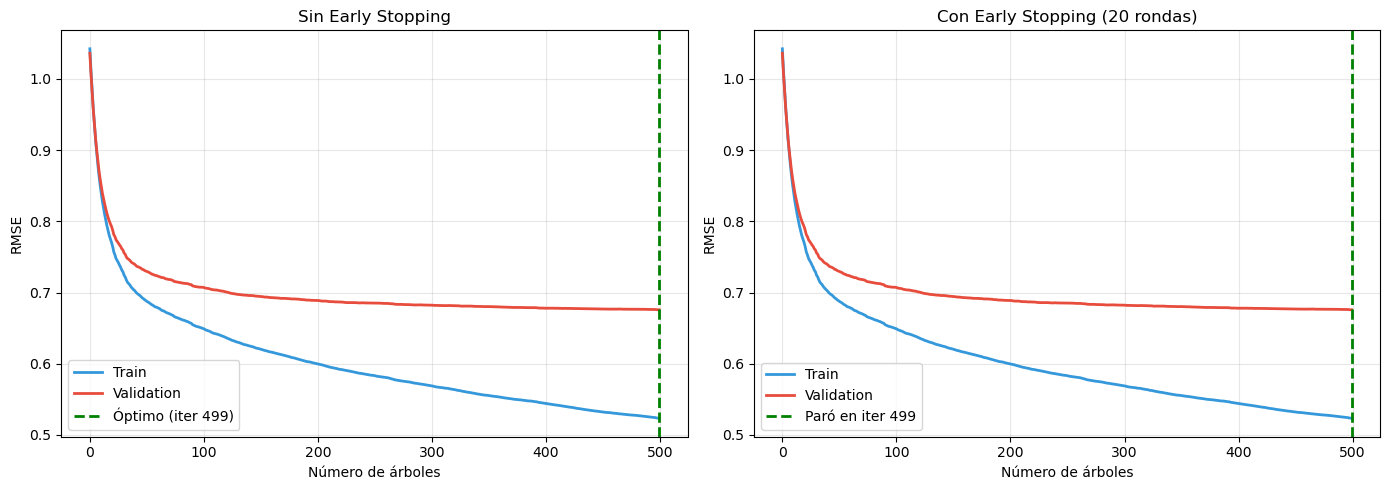
Early Stopping: Detención Automática
Una técnica crucial para Gradient Boosting es early stopping: detener el entrenamiento cuando el error de validación deja de mejorar, en lugar de especificar un número fijo de iteraciones.
# Dividir train en train/validation para early stoppingX_train_sub, X_val, y_train_sub, y_val = train_test_split( X_train, y_train, test_size=0.2, random_state=42)# Entrenar con muchas iteraciones para ver el efectogb_early = GradientBoostingRegressor( n_estimators=300, max_depth=3, learning_rate=0.1, random_state=42)gb_early.fit(X_train_sub, y_train_sub)# Calcular errores en cada etapatrain_errors_es = []val_errors_es = []for y_pred_train, y_pred_val inzip(gb_early.staged_predict(X_train_sub), gb_early.staged_predict(X_val)): train_errors_es.append(np.sqrt(mean_squared_error(y_train_sub, y_pred_train))) val_errors_es.append(np.sqrt(mean_squared_error(y_val, y_pred_val)))# Simular early stopping: encontrar cuando val error deja de mejorarpatience =20best_val_error =float('inf')best_iteration =0no_improvement_count =0for i, val_error inenumerate(val_errors_es):if val_error < best_val_error: best_val_error = val_error best_iteration = i +1 no_improvement_count =0else: no_improvement_count +=1if no_improvement_count >= patience: early_stop_iteration = i +1breakelse: early_stop_iteration =len(val_errors_es)# Visualizarplt.figure(figsize=(10, 5))plt.plot(range(1, len(train_errors_es) +1), train_errors_es,'b-', linewidth=2, label='Error Train', alpha=0.7)plt.plot(range(1, len(val_errors_es) +1), val_errors_es,'r-', linewidth=2, label='Error Validación', alpha=0.7)# Marcar mejor puntoplt.axvline(x=best_iteration, color='green', linestyle='--', linewidth=2, alpha=0.7)plt.plot(best_iteration, val_errors_es[best_iteration-1], 'go', markersize=12)# Marcar donde early stopping detendríaplt.axvline(x=early_stop_iteration, color='orange', linestyle=':', linewidth=2, alpha=0.7)# Área de sobreajusteif early_stop_iteration <280: plt.axvspan(early_stop_iteration, 300, alpha=0.2, color='red') plt.text(early_stop_iteration +10, 0.45, 'Zona de sobreajuste\n(sin beneficio)', fontsize=10, color='darkred', fontweight='bold')plt.text(best_iteration +5, val_errors_es[best_iteration-1] +0.02,f'Mejor: iter. {best_iteration}\nRMSE = {val_errors_es[best_iteration-1]:.4f}\n'+f'Early stop: iter. {early_stop_iteration}\n(patience={patience})', fontsize=9, color='green', fontweight='bold', bbox=dict(boxstyle='round', facecolor='lightgreen', alpha=0.7))plt.xlabel('Número de iteraciones', fontsize=11)plt.ylabel('RMSE', fontsize=11)plt.title('Early Stopping en Gradient Boosting', fontsize=12, fontweight='bold')plt.legend(fontsize=10)plt.grid(True, alpha=0.3)plt.xlim([0, 300])plt.tight_layout()plt.show()print(f"\n{'='*60}")print(f"EARLY STOPPING ANALYSIS")print(f"{'='*60}")print(f"Mejor iteración (mínimo error val): {best_iteration}")print(f"Early stopping (patience={patience}): iter. {early_stop_iteration}")print(f"Iteraciones ahorradas: {300- early_stop_iteration}")print(f"RMSE en mejor punto: {val_errors_es[best_iteration-1]:.4f}")print(f"RMSE si usáramos todas (300): {val_errors_es[-1]:.4f}")print(f"Diferencia: {val_errors_es[-1] - val_errors_es[best_iteration-1]:.4f} (peor)")print(f"{'='*60}\n")
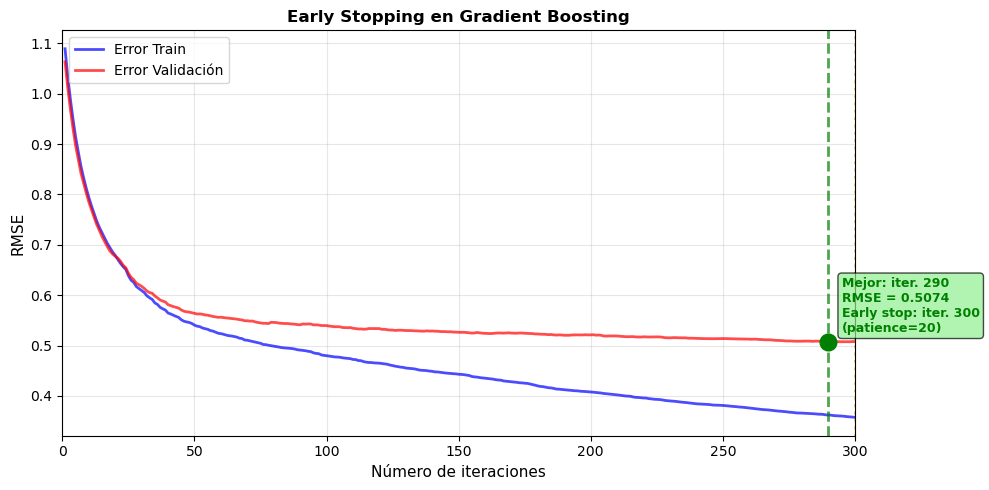
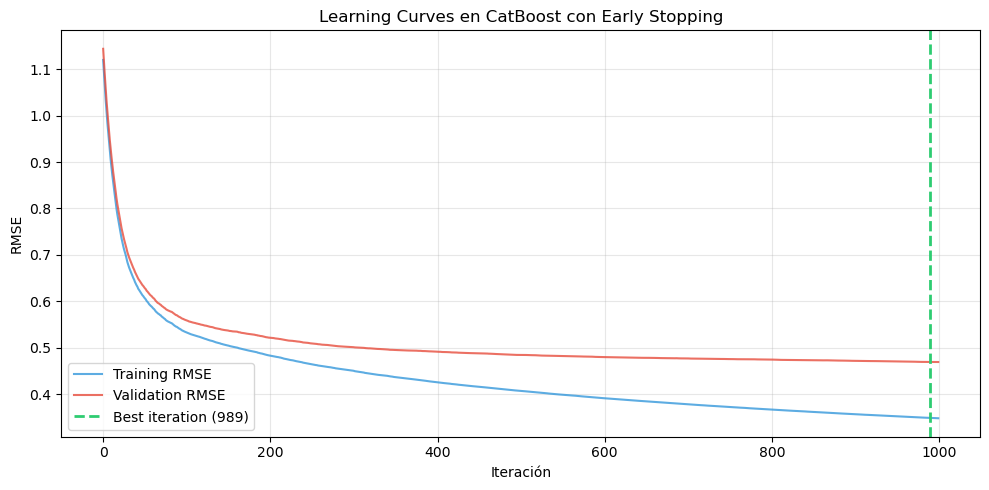
Figura 10.9: Demostración de early stopping en Gradient Boosting. La línea azul muestra el error de entrenamiento (que continúa disminuyendo), mientras que la línea roja muestra el error de validación. El punto verde marca donde early stopping detendría el entrenamiento (cuando el error de validación no mejora por 20 iteraciones consecutivas). Continuar más allá de este punto lleva a sobreajuste sin beneficio en generalización.
============================================================
EARLY STOPPING ANALYSIS
============================================================
Mejor iteración (mínimo error val): 290
Early stopping (patience=20): iter. 300
Iteraciones ahorradas: 0
RMSE en mejor punto: 0.5074
RMSE si usáramos todas (300): 0.5079
Diferencia: 0.0005 (peor)
============================================================
Cómo implementar early stopping en scikit-learn:
from sklearn.model_selection import train_test_split# Dividir datos en train/validation/testX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)X_train_sub, X_val, y_train_sub, y_val = train_test_split( X_train, y_train, test_size=0.2)# Opción 1: Monitoreo manual con staged_predictgb = GradientBoostingRegressor(n_estimators=1000, learning_rate=0.1)gb.fit(X_train_sub, y_train_sub)val_errors = [mean_squared_error(y_val, y_pred)for y_pred in gb.staged_predict(X_val)]best_n = np.argmin(val_errors) +1# Reentrenar con número óptimogb_final = GradientBoostingRegressor(n_estimators=best_n, learning_rate=0.1)gb_final.fit(X_train, y_train)# Opción 2: Usar n_iter_no_change (sklearn >= 0.20)gb_auto = GradientBoostingRegressor( n_estimators=1000, learning_rate=0.1, validation_fraction=0.2, # Separa automáticamente validación n_iter_no_change=20, # Patience tol=0.0001# Mejora mínima considerada significativa)gb_auto.fit(X_train, y_train)print(f"Iteraciones usadas: {gb_auto.n_estimators_}")
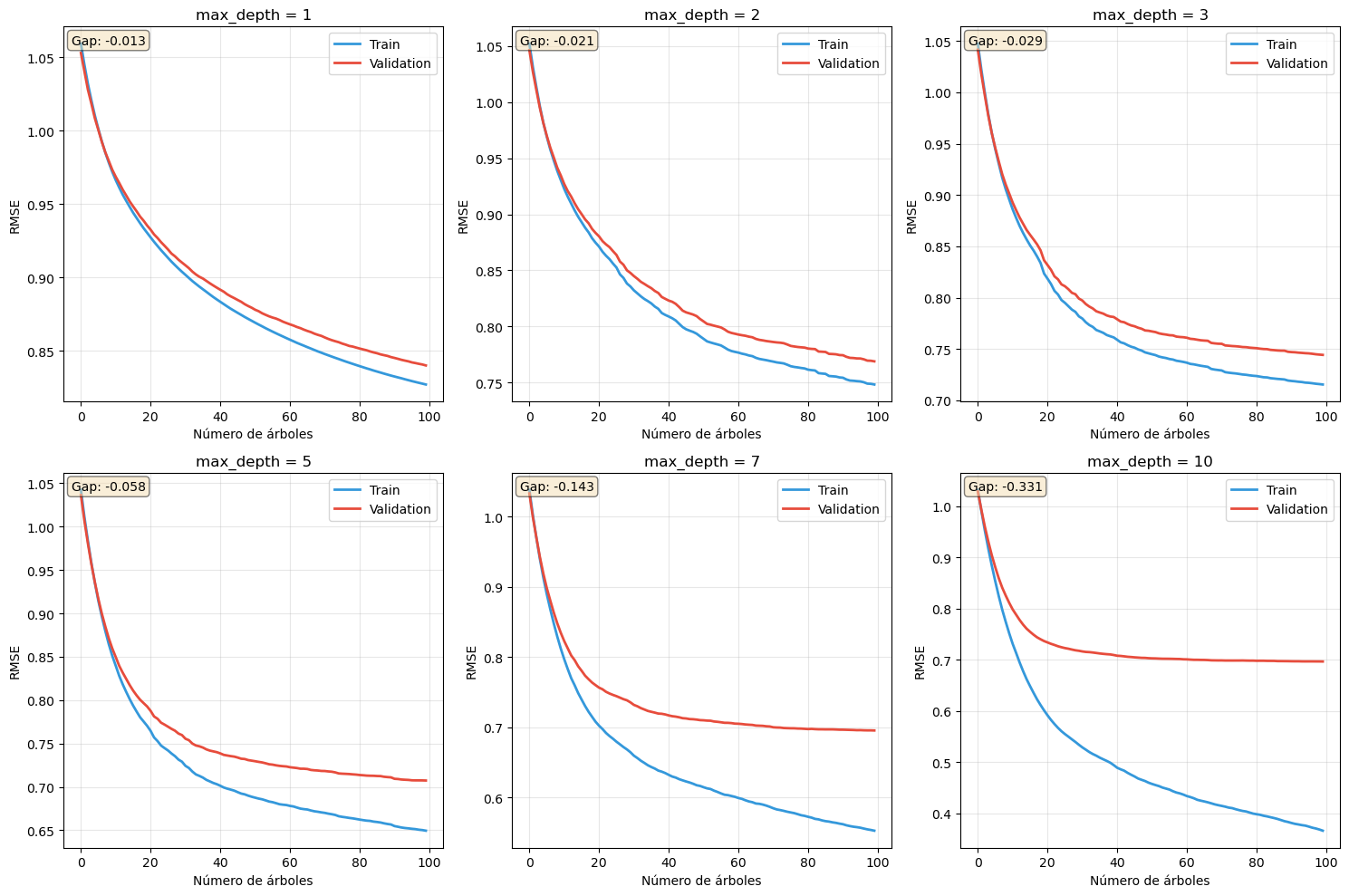
Cuidado con el Sobreajuste en Gradient Boosting
Gradient Boosting puede sobreajustar fácilmente si no se regula adecuadamente. Las señales de advertencia incluyen:
Síntomas de sobreajuste:
Gap grande y creciente entre error de train y test
Rendimiento en test empeora mientras train mejora
Modelo muy sensible a pequeños cambios en hiperparámetros
Predicciones extrañas en regiones con pocos datos
Causas comunes:
Demasiadas iteraciones sin early stopping
Árboles muy profundos (max_depth > 5-7)
Learning rate muy alto (>0.3) con muchas iteraciones
min_samples_leaf muy bajo (<5)
Datos con ruido o outliers (usar funciones de pérdida robustas)
Soluciones:
✅ Siempre usar early stopping con conjunto de validación
✅ Reducir max_depth (empezar con 3)
✅ Reducir learning_rate y compensar con más iteraciones
✅ Aumentar min_samples_split y min_samples_leaf
✅ Usar subsample < 1.0 (típicamente 0.5-0.8)
✅ Usar regularización: max_features < n_features
✅ Si el sobreajuste persiste, considerar Random Forest
Regla de oro: Si dudas entre sobreajustar o subajustar, es mejor subajustar ligeramente. Un modelo simple que generaliza es preferible a uno complejo que memoriza.
Feature Importance e Interpretabilidad
Una ventaja de Gradient Boosting es que permite analizar la importancia relativa de las features:
# Entrenar modelo óptimogb_final = GradientBoostingRegressor( n_estimators=100, max_depth=3, learning_rate=0.1, random_state=42)gb_final.fit(X_train, y_train)# Obtener nombres de featuresfeature_names = california.feature_names# Feature importanceimportances = gb_final.feature_importances_indices = np.argsort(importances)[::-1]# Visualizarplt.figure(figsize=(10, 5))plt.bar(range(len(importances)), importances[indices], alpha=0.8, color='steelblue')plt.xticks(range(len(importances)), [feature_names[i] for i in indices], rotation=45, ha='right')plt.xlabel('Feature', fontsize=11)plt.ylabel('Importancia (reducción de MSE)', fontsize=11)plt.title('Feature Importance en Gradient Boosting (California Housing)', fontsize=12, fontweight='bold')plt.grid(True, alpha=0.3, axis='y')plt.tight_layout()plt.show()# Imprimir rankingprint(f"\n{'='*50}")print(f"RANKING DE FEATURE IMPORTANCE")print(f"{'='*50}")for i, idx inenumerate(indices, 1):print(f"{i}. {feature_names[idx]:15s}: {importances[idx]:.4f}")print(f"{'='*50}\n")
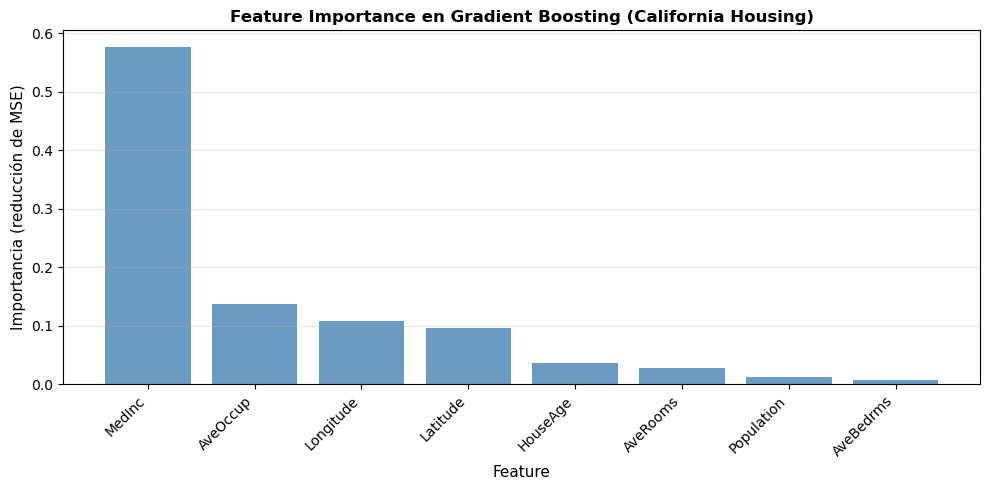
Figura 10.10: Análisis de importancia de features en Gradient Boosting usando el dataset California Housing. Las features más importantes son MedInc (ingreso mediano) y AveOccup (ocupación promedio), seguidas por la ubicación geográfica. La importancia se calcula como la reducción total de error atribuida a cada feature sumada sobre todos los árboles del ensamble.
Interpretación de feature importance en Gradient Boosting:
Valores altos: Features que contribuyen significativamente a reducir el error en múltiples splits
Cálculo: Suma ponderada de la reducción de error en cada split que usa esa feature, a través de todos los árboles
Uso práctico:
Identificar features más predictivas
Ingeniería de features (crear interacciones de features importantes)
Selección de features (eliminar features con importancia cercana a cero)
Comunicación con stakeholders (explicar qué factores impulsan las predicciones)
En resumen, Gradient Boosting es un framework extremadamente flexible y poderoso que generaliza AdaBoost, permitiendo optimizar cualquier función de pérdida diferenciable. Sus principales fortalezas son la flexibilidad en la elección de pérdida y la capacidad de control fino mediante hiperparámetros. Sin embargo, requiere más cuidado que Random Forest para evitar sobreajuste, y el tuning de hiperparámetros es más crítico para obtener buen rendimiento.
En las siguientes secciones exploraremos implementaciones modernas de gradient boosting (XGBoost, LightGBM, CatBoost) que optimizan velocidad, uso de memoria, y añaden características adicionales para facilitar su uso en producción.
5. Implementaciones Modernas de Boosting
Aunque las implementaciones clásicas de AdaBoost y Gradient Boosting en scikit-learn son excelentes para entender los conceptos fundamentales, en la práctica moderna se utilizan implementaciones optimizadas que ofrecen mejoras significativas en velocidad, uso de memoria, capacidad de regularización y facilidad de uso. En esta sección exploraremos tres de las bibliotecas más populares y poderosas: XGBoost, LightGBM y CatBoost.
Estas implementaciones han dominado competencias de machine learning como Kaggle y se utilizan ampliamente en producción debido a su rendimiento superior. Cada una introduce innovaciones algorítmicas y de ingeniería que las hacen más eficientes que las implementaciones base.
5.1 XGBoost (eXtreme Gradient Boosting)
XGBoost, desarrollado por Tianqi Chen en 2014, es probablemente la implementación de boosting más popular y ampliamente utilizada en la industria. Su éxito se debe a una combinación de innovaciones algorítmicas, optimizaciones de ingeniería, y una API bien diseñada que facilita su uso en producción.
¿Qué hace especial a XGBoost?
XGBoost introduce varias mejoras clave sobre el gradient boosting tradicional:
1. Regularización en la función objetivo
XGBoost añade términos de regularización explícitos a la función objetivo que se optimiza en cada iteración:
\(\gamma\) = penalización por número de hojas (complejidad del árbol)
\(\lambda\) = regularización L2 sobre los pesos de las hojas
\(\alpha\) = regularización L1 sobre los pesos de las hojas
Esta regularización ayuda a prevenir sobreajuste de manera más efectiva que simplemente limitar la profundidad del árbol.
2. Optimización de segundo orden (Newton Boosting)
Mientras que el gradient boosting clásico solo usa la primera derivada (gradiente) de la función de pérdida, XGBoost usa también la segunda derivada (Hessian). Esto proporciona información sobre la curvatura de la función de pérdida y permite una optimización más precisa y rápida, similar a cómo el método de Newton es más eficiente que el descenso por gradiente.
3. Construcción de árbol eficiente
XGBoost utiliza algoritmos optimizados para encontrar los mejores splits:
Exact greedy algorithm: Enumera todos los posibles split points (para datasets pequeños)
Approximate algorithm: Usa histogramas y quantiles para proponer candidatos de split (para datasets grandes)
Sparsity-aware algorithm: Maneja eficientemente missing values y features sparse
4. Poda de árbol con max_delta_step
En lugar de limitar la profundidad durante la construcción, XGBoost puede construir árboles profundos y luego podarlos hacia atrás, eliminando splits que no aportan ganancia suficiente después de considerar la regularización.
5. Parallel y Distributed Computing
XGBoost paraleliza la construcción de árboles a nivel de features (no de árboles, ya que boosting es secuencial). También soporta entrenamiento distribuido y puede usar GPUs.
XGBoost en competencias
XGBoost ha sido el algoritmo ganador o parte de la solución ganadora en la mayoría de competencias de Kaggle que involucran datos tabulares desde 2015. Su combinación de precisión, velocidad y flexibilidad lo ha convertido en el punto de partida estándar para estos problemas.
Hiperparámetros importantes en XGBoost
XGBoost tiene muchos hiperparámetros, pero los más importantes son:
Estructura del árbol:
max_depth: Profundidad máxima de cada árbol (típicamente 3-10)
min_child_weight: Suma mínima de weights (Hessian) en una hoja (análogo a min_samples_leaf)
gamma: Reducción mínima de loss necesaria para hacer un split (mayor = más conservador)
Regularización:
lambda (reg_lambda): Regularización L2 en pesos de hojas (default = 1)
alpha (reg_alpha): Regularización L1 en pesos de hojas (default = 0)
Muestreo:
subsample: Fracción de samples a usar por árbol (0.5-1.0)
colsample_bytree: Fracción de features a usar por árbol (0.5-1.0)
colsample_bylevel: Fracción de features a usar por nivel del árbol
Proceso de boosting:
learning_rate (eta): Shrinkage de cada árbol (típicamente 0.01-0.3)
n_estimators: Número de árboles a construir
objective: Función de pérdida a optimizar
Ejemplos prácticos con XGBoost
Comencemos con un ejemplo de clasificación comparando XGBoost con Gradient Boosting de scikit-learn:
Ahora veamos un ejemplo de regresión con California Housing, mostrando diferentes tipos de feature importance en XGBoost:
from sklearn.datasets import fetch_california_housingimport pandas as pd# Cargar datoshousing = fetch_california_housing()X = pd.DataFrame(housing.data, columns=housing.feature_names)y = housing.targetX_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42)# Entrenar modelo XGBoostxgb_reg = xgb.XGBRegressor( n_estimators=100, learning_rate=0.1, max_depth=5, random_state=42)xgb_reg.fit(X_train, y_train)# Obtener diferentes tipos de importanceimportance_types = ['weight', 'gain', 'cover']importances = {}for imp_type in importance_types: importances[imp_type] = xgb_reg.get_booster().get_score( importance_type=imp_type )# Visualizarfig, axes = plt.subplots(1, 3, figsize=(15, 4))for idx, imp_type inenumerate(importance_types): imp_df = pd.DataFrame({'feature': list(importances[imp_type].keys()),'importance': list(importances[imp_type].values()) }).sort_values('importance', ascending=True) axes[idx].barh(imp_df['feature'], imp_df['importance'], color='#2ecc71') axes[idx].set_xlabel('Importance') axes[idx].set_title(f'Importance Type: {imp_type.upper()}') axes[idx].grid(axis='x', alpha=0.3)plt.tight_layout()plt.show()print("\nTipos de Feature Importance en XGBoost:")print("- WEIGHT: Número de veces que la feature aparece en un split")print("- GAIN: Ganancia promedio (reducción de loss) cuando se usa la feature")print("- COVER: Cobertura promedio (número de observaciones afectadas)")
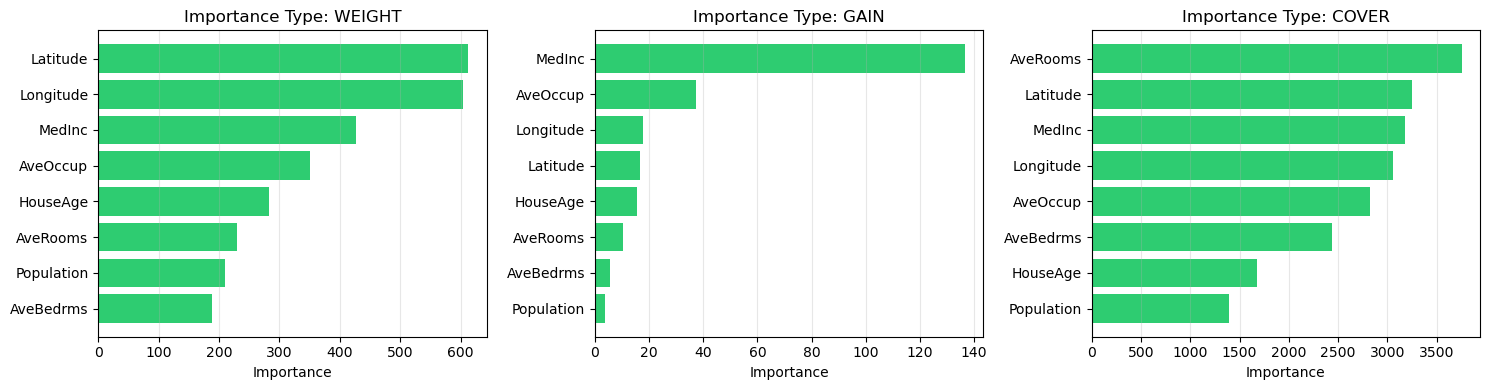
Diferentes tipos de feature importance en XGBoost
Tipos de Feature Importance en XGBoost:
- WEIGHT: Número de veces que la feature aparece en un split
- GAIN: Ganancia promedio (reducción de loss) cuando se usa la feature
- COVER: Cobertura promedio (número de observaciones afectadas)
Ahora demostremos early stopping y validación cruzada integrada:
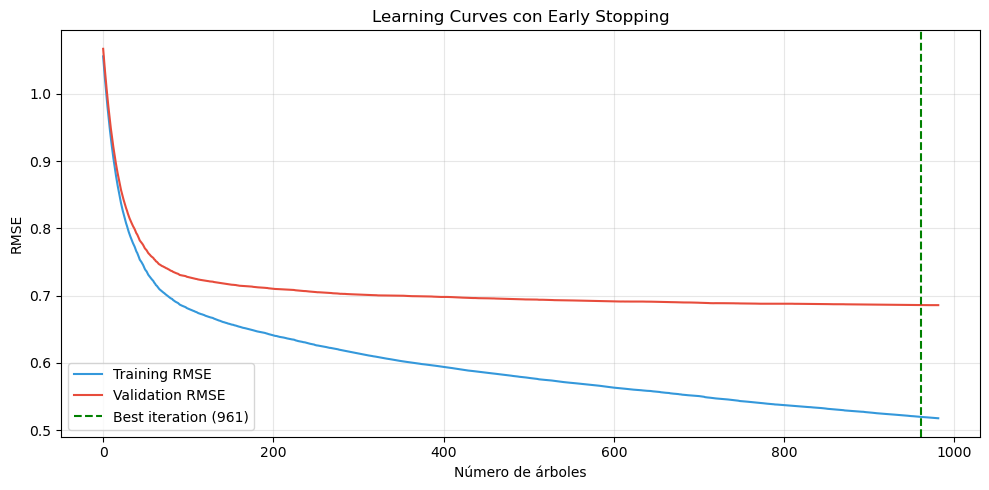
# Crear validation setX_train_sub, X_val, y_train_sub, y_val = train_test_split( X_train, y_train, test_size=0.2, random_state=42)# Modelo con early stoppingxgb_early = xgb.XGBRegressor( n_estimators=1000, # Número grande, early stopping decidirá cuándo parar learning_rate=0.05, max_depth=5, random_state=42, early_stopping_rounds=20# Parar si no mejora en 20 rondas)# Entrenar con validation seteval_set = [(X_train_sub, y_train_sub), (X_val, y_val)]xgb_early.fit( X_train_sub, y_train_sub, eval_set=eval_set, verbose=False)# Obtener resultados de evaluaciónresults = xgb_early.evals_result()train_rmse = np.sqrt(results['validation_0']['rmse'])val_rmse = np.sqrt(results['validation_1']['rmse'])# Visualizar learning curvesplt.figure(figsize=(10, 5))plt.plot(train_rmse, label='Training RMSE', color='#3498db')plt.plot(val_rmse, label='Validation RMSE', color='#e74c3c')plt.axvline( x=xgb_early.best_iteration, color='green', linestyle='--', label=f'Best iteration ({xgb_early.best_iteration})')plt.xlabel('Número de árboles')plt.ylabel('RMSE')plt.title('Learning Curves con Early Stopping')plt.legend()plt.grid(alpha=0.3)plt.tight_layout()plt.show()print(f"Mejor iteración: {xgb_early.best_iteration}")print(f"Mejor score de validación: {xgb_early.best_score:.4f}")print(f"Árboles ahorrados: {1000- xgb_early.best_iteration}")
Early stopping en XGBoost con conjunto de validación
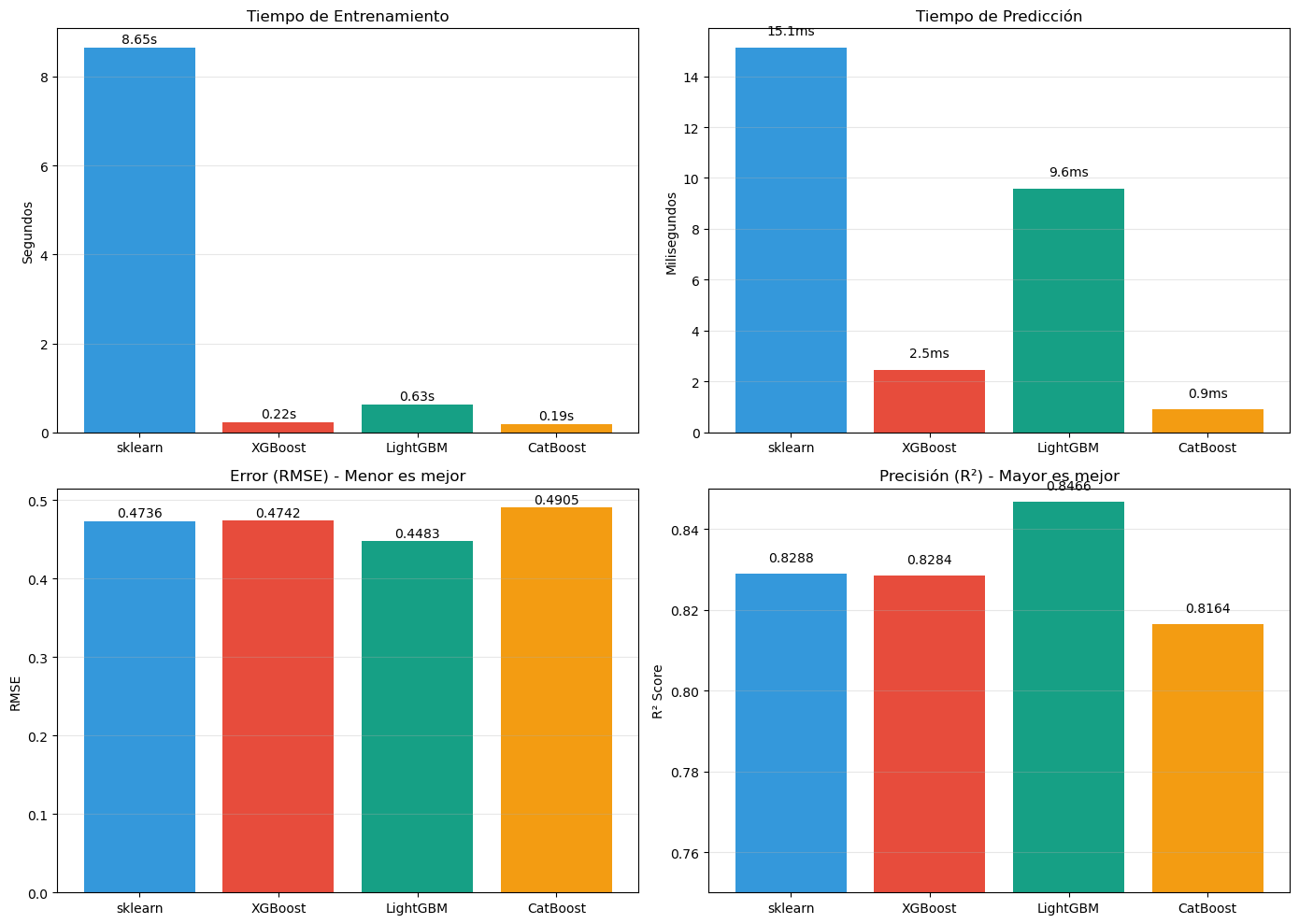
Mejor iteración: 961
Mejor score de validación: 0.4705
Árboles ahorrados: 39
5.2 LightGBM (Light Gradient Boosting Machine)
LightGBM, desarrollado por Microsoft Research en 2017, es una implementación de gradient boosting diseñada específicamente para ser extremadamente rápida y eficiente en memoria. Está optimizada para datasets grandes (más de 10,000 muestras y cientos o miles de features) y es particularmente efectiva cuando la velocidad de entrenamiento es crítica.
El nombre “Light” no se refiere a que sea una versión simplificada, sino a que es “ligera” en términos de uso de recursos computacionales mientras mantiene (o incluso supera) la precisión de otros métodos de boosting.
Innovaciones clave de LightGBM
1. GOSS (Gradient-based One-Side Sampling)
Una de las innovaciones más importantes de LightGBM es su estrategia de muestreo inteligente:
Problema: En un dataset grande, calcular el mejor split considerando todas las muestras es costoso
Solución: No todas las muestras son igualmente importantes para encontrar el mejor split
GOSS funciona así:
Ordena las muestras por el valor absoluto de sus gradientes
Mantiene todas las muestras con gradientes grandes (errores grandes)
Muestrea aleatoriamente una fracción de las muestras con gradientes pequeños
Cuando calcula el gain, compensa las muestras pequeñas con un factor multiplicador
La intuición es que las muestras mal predichas (gradientes grandes) son más informativas para encontrar buenos splits, mientras que las muestras bien predichas contribuyen menos a la decisión del split.
2. EFB (Exclusive Feature Bundling)
Otra innovación para reducir el número de features efectivas:
Observación: En datasets con muchas features sparse (muchos ceros), varias features nunca toman valores no-cero simultáneamente
Solución: Agrupar features mutuamente exclusivas en un solo “bundle”
Resultado: Reducir el número de features sin pérdida de información
Por ejemplo, en datos de one-hot encoding, múltiples columnas pueden agruparse porque solo una puede ser 1 a la vez.
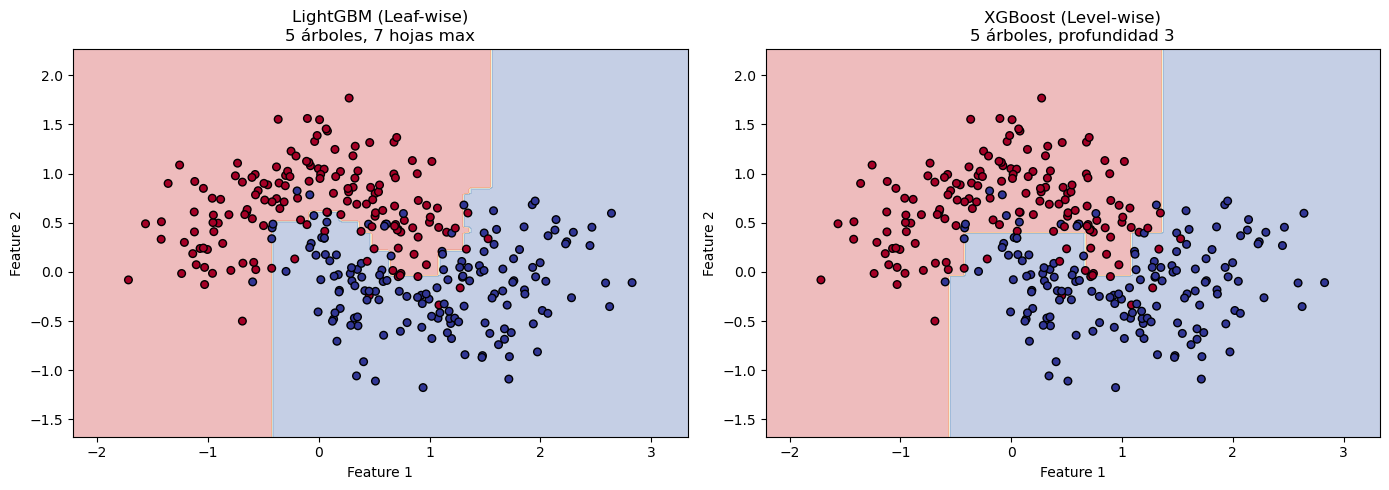
3. Leaf-wise Tree Growth (vs Level-wise)
Esta es probablemente la diferencia más visible con XGBoost:
Level-wise (XGBoost, sklearn): Crece el árbol nivel por nivel, dividiendo todos los nodos del mismo nivel
Leaf-wise (LightGBM): Crece el árbol dividiendo la hoja que maximiza la reducción de pérdida, independientemente del nivel
Generalmente alcanza menor loss con el mismo número de splits
Más eficiente computacionalmente
Desventaja:
Puede sobreajustar más fácilmente creando árboles muy profundos y desbalanceados
Se controla con max_depth y num_leaves
4. Histogram-based Learning
En lugar de buscar el mejor split considerando todos los valores posibles:
Discretiza features continuas en bins (histogramas de valores)
Solo considera los límites de bins como candidatos para splits
Reduce complejidad de \(O(\#data \times \#features)\) a \(O(\#bins \times \#features)\)
También reduce uso de memoria considerablemente
Hiperparámetros importantes en LightGBM
LightGBM tiene algunos hiperparámetros únicos además de los estándar:
Específicos de LightGBM:
num_leaves: Número máximo de hojas por árbol (más importante que max_depth)
min_data_in_leaf: Mínimo de samples en una hoja (previene overfitting)
bagging_fraction / subsample: Fracción de datos para cada árbol
feature_fraction / colsample_bytree: Fracción de features para cada árbol
max_bin: Número de bins para histogram-based learning
Regularización:
lambda_l1: Regularización L1
lambda_l2: Regularización L2
min_gain_to_split: Ganancia mínima para hacer un split
Control de velocidad:
num_threads: Número de threads paralelos
device_type: ‘cpu’ o ‘gpu’
num_leaves vs max_depth
En LightGBM, num_leaves es más importante que max_depth debido al crecimiento leaf-wise. Una regla general es: \[\text{num\_leaves} \leq 2^{\text{max\_depth}}\]
Un árbol con max_depth=5 podría tener hasta 32 hojas, pero típicamente queremos menos (e.g., num_leaves=31) para mejor generalización.
Ejemplos prácticos con LightGBM
Comencemos comparando la velocidad de LightGBM con XGBoost en un dataset grande:
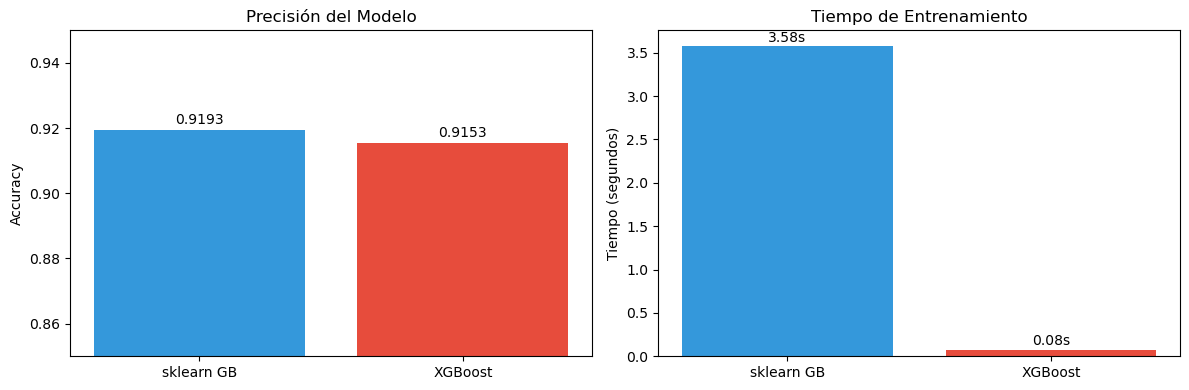
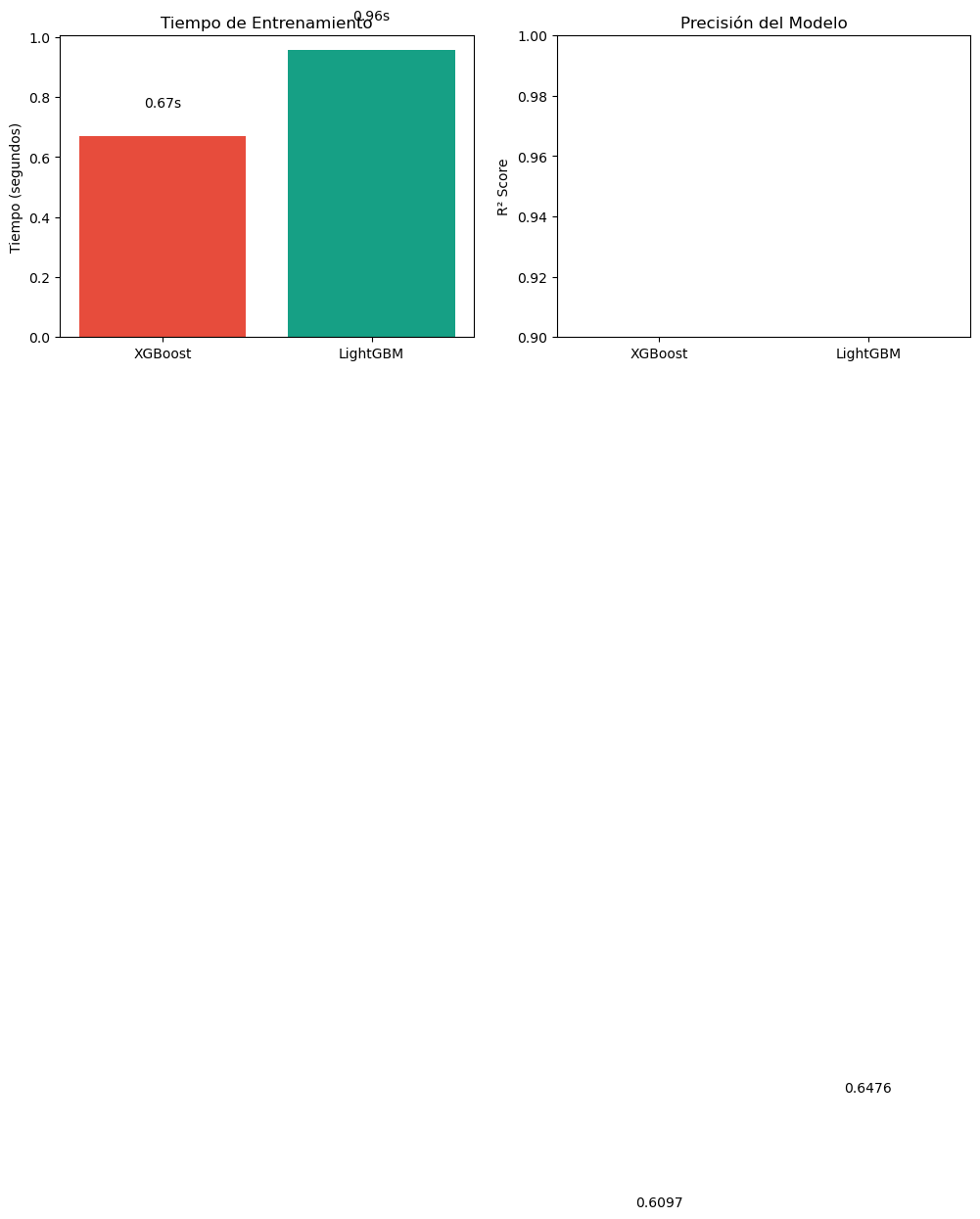
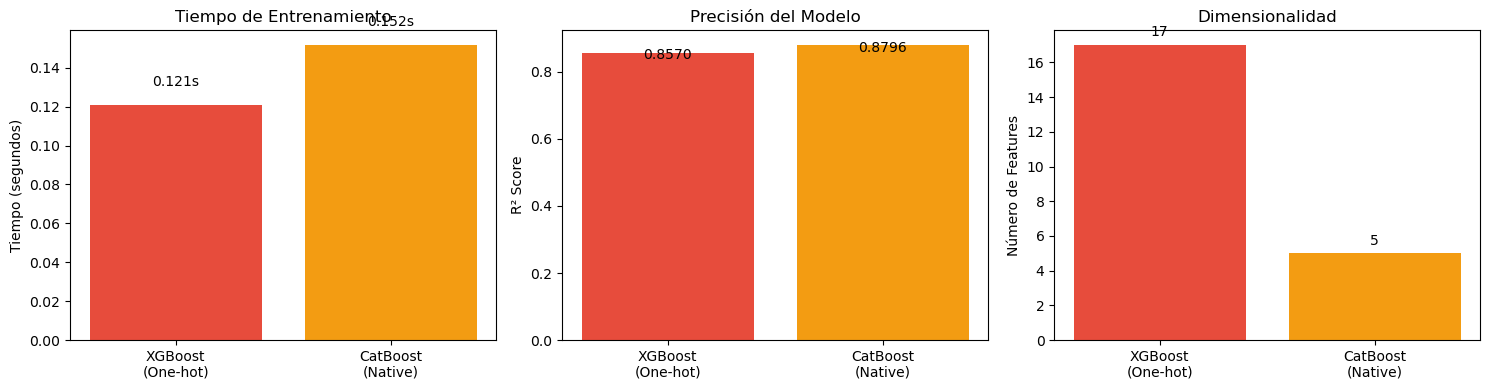
import lightgbm as lgbfrom sklearn.datasets import make_regressionimport time# Crear dataset más grande para ver diferencias de velocidadX_large, y_large = make_regression( n_samples=50000, n_features=100, n_informative=80, random_state=42)X_train_l, X_test_l, y_train_l, y_test_l = train_test_split( X_large, y_large, test_size=0.2, random_state=42)# Parámetros comparablesn_estimators =100# XGBoostprint("Entrenando XGBoost...")start = time.time()xgb_large = xgb.XGBRegressor( n_estimators=n_estimators, learning_rate=0.1, max_depth=5, random_state=42, verbosity=0)xgb_large.fit(X_train_l, y_train_l)time_xgb = time.time() - startscore_xgb = xgb_large.score(X_test_l, y_test_l)# LightGBMprint("Entrenando LightGBM...")start = time.time()lgb_model = lgb.LGBMRegressor( n_estimators=n_estimators, learning_rate=0.1, num_leaves=31, # Aproximadamente 2^5 random_state=42, verbose=-1)lgb_model.fit(X_train_l, y_train_l)time_lgb = time.time() - startscore_lgb = lgb_model.score(X_test_l, y_test_l)# Visualizar comparaciónfig, axes = plt.subplots(1, 2, figsize=(12, 4))models = ['XGBoost', 'LightGBM']times = [time_xgb, time_lgb]scores = [score_xgb, score_lgb]# Tiempoaxes[0].bar(models, times, color=['#e74c3c', '#16a085'])axes[0].set_ylabel('Tiempo (segundos)')axes[0].set_title('Tiempo de Entrenamiento')for i, t inenumerate(times): axes[0].text(i, t +0.1, f'{t:.2f}s', ha='center', fontsize=10)# Score (R²)axes[1].bar(models, scores, color=['#e74c3c', '#16a085'])axes[1].set_ylabel('R² Score')axes[1].set_title('Precisión del Modelo')axes[1].set_ylim([0.9, 1.0])for i, s inenumerate(scores): axes[1].text(i, s +0.002, f'{s:.4f}', ha='center', fontsize=10)plt.tight_layout()plt.show()print(f"\nDataset: {X_large.shape[0]:,} samples, {X_large.shape[1]} features")print(f"XGBoost : {time_xgb:.2f}s, R² = {score_xgb:.4f}")print(f"LightGBM : {time_lgb:.2f}s, R² = {score_lgb:.4f}")print(f"Speedup : {time_xgb/time_lgb:.2f}x más rápido")
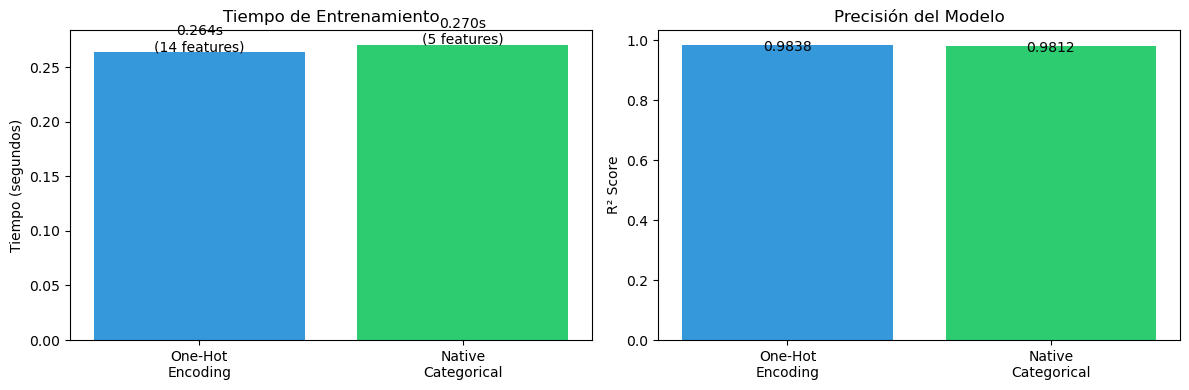
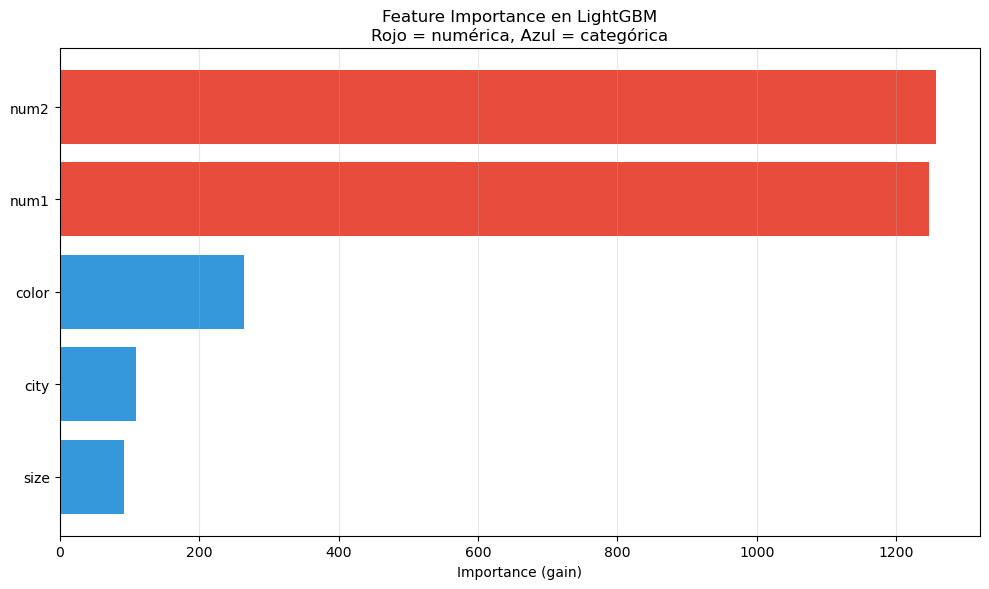
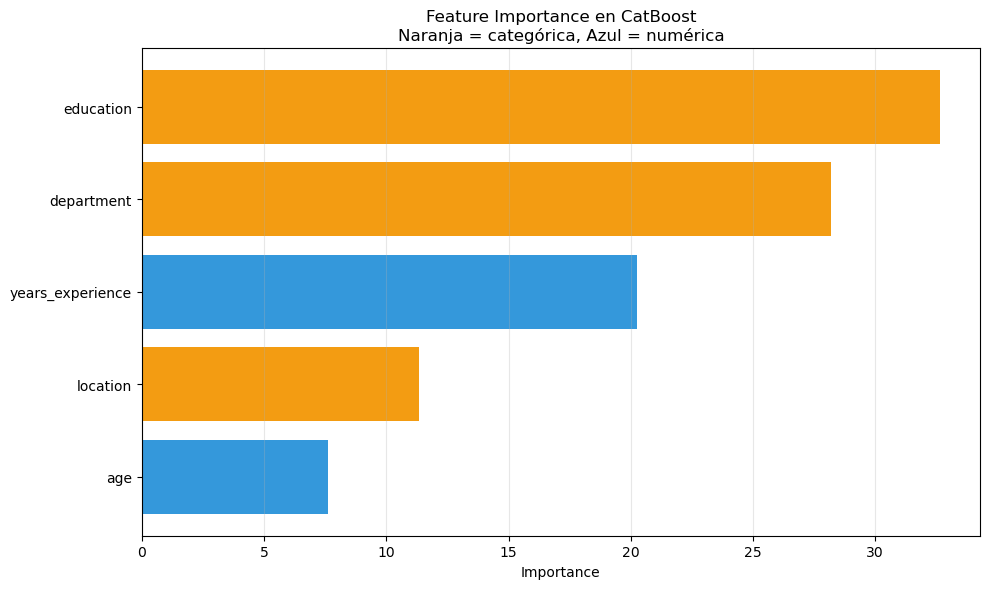
Veamos el manejo nativo de categorical features en LightGBM:
# Crear dataset con features categóricasnp.random.seed(42)n_samples =1000# Features categóricas simuladascities = np.random.choice(['NY', 'LA', 'Chicago', 'Houston', 'Phoenix'], n_samples)colors = np.random.choice(['Red', 'Blue', 'Green'], n_samples)sizes = np.random.choice(['S', 'M', 'L', 'XL'], n_samples)# Features numéricasnum_feat1 = np.random.randn(n_samples)num_feat2 = np.random.randn(n_samples)# Target: función compleja de todas las featuresy_cat = ( (cities =='NY').astype(int) *10+ (colors =='Red').astype(int) *5+ (sizes =='L').astype(int) *3+ num_feat1 *2+ num_feat2 *1.5+ np.random.randn(n_samples) *0.5)# Crear DataFramedf_cat = pd.DataFrame({'city': cities,'color': colors,'size': sizes,'num1': num_feat1,'num2': num_feat2,'target': y_cat})# Splittrain_df, test_df = train_test_split(df_cat, test_size=0.2, random_state=42)# Método 1: One-hot encoding (tradicional)X_train_onehot = pd.get_dummies( train_df.drop('target', axis=1), columns=['city', 'color', 'size'])X_test_onehot = pd.get_dummies( test_df.drop('target', axis=1), columns=['city', 'color', 'size'])# Asegurar mismas columnasX_test_onehot = X_test_onehot.reindex(columns=X_train_onehot.columns, fill_value=0)start = time.time()lgb_onehot = lgb.LGBMRegressor(n_estimators=100, random_state=42, verbose=-1)lgb_onehot.fit(X_train_onehot, train_df['target'])time_onehot = time.time() - startscore_onehot = lgb_onehot.score(X_test_onehot, test_df['target'])# Método 2: Categorical encoding nativo de LightGBM# Convertir a categoríasfor col in ['city', 'color', 'size']: train_df[col] = train_df[col].astype('category') test_df[col] = test_df[col].astype('category')X_train_cat = train_df.drop('target', axis=1)X_test_cat = test_df.drop('target', axis=1)start = time.time()lgb_cat = lgb.LGBMRegressor(n_estimators=100, random_state=42, verbose=-1)lgb_cat.fit( X_train_cat, train_df['target'], categorical_feature=['city', 'color', 'size'])time_cat = time.time() - startscore_cat = lgb_cat.score(X_test_cat, test_df['target'])# Comparar resultadosfig, axes = plt.subplots(1, 2, figsize=(12, 4))methods = ['One-Hot\nEncoding', 'Native\nCategorical']times = [time_onehot, time_cat]scores = [score_onehot, score_cat]n_features = [X_train_onehot.shape[1], X_train_cat.shape[1]]axes[0].bar(methods, times, color=['#3498db', '#2ecc71'])axes[0].set_ylabel('Tiempo (segundos)')axes[0].set_title('Tiempo de Entrenamiento')for i, (t, n) inenumerate(zip(times, n_features)): axes[0].text(i, t +0.001, f'{t:.3f}s\n({n} features)', ha='center')axes[1].bar(methods, scores, color=['#3498db', '#2ecc71'])axes[1].set_ylabel('R² Score')axes[1].set_title('Precisión del Modelo')for i, s inenumerate(scores): axes[1].text(i, s -0.02, f'{s:.4f}', ha='center')plt.tight_layout()plt.show()print("\nComparación:")print(f"One-hot encoding: {X_train_onehot.shape[1]} features, R² = {score_onehot:.4f}, {time_onehot:.3f}s")print(f"Native categorical: {X_train_cat.shape[1]} features, R² = {score_cat:.4f}, {time_cat:.3f}s")print(f"\nVentajas del manejo nativo:")print("- Menos features (no explosión dimensional)")print("- Más rápido")print("- Mejor o similar precisión")print("- Automático (no requiere preprocesamiento manual)")
Manejo de features categóricas en LightGBM
Comparación:
One-hot encoding: 14 features, R² = 0.9838, 0.264s
Native categorical: 5 features, R² = 0.9812, 0.270s
Ventajas del manejo nativo:
- Menos features (no explosión dimensional)
- Más rápido
- Mejor o similar precisión
- Automático (no requiere preprocesamiento manual)
Feature importance en LightGBM:
# Usar el modelo categórico anterior# Obtener importancesimportances = lgb_cat.feature_importances_feature_names = X_train_cat.columns# Crear DataFrame y ordenarimp_df = pd.DataFrame({'feature': feature_names,'importance': importances}).sort_values('importance', ascending=True)# Visualizarplt.figure(figsize=(10, 6))colors = ['#e74c3c'if'num'in f else'#3498db'for f in imp_df['feature']]plt.barh(imp_df['feature'], imp_df['importance'], color=colors)plt.xlabel('Importance (gain)')plt.title('Feature Importance en LightGBM\nRojo = numérica, Azul = categórica')plt.grid(axis='x', alpha=0.3)plt.tight_layout()plt.show()# Mostrar valoresprint("\nFeature Importances:")for feat, imp inzip(imp_df['feature'], imp_df['importance']):print(f" {feat:15s}: {imp:8.2f}")
Feature importance en LightGBM
Feature Importances:
size : 93.00
city : 109.00
color : 264.00
num1 : 1246.00
num2 : 1257.00
Cuándo usar LightGBM
Usa LightGBM cuando:
Tienes datasets grandes (>10,000 muestras, >100 features)
La velocidad de entrenamiento es crítica
Tienes muchas features categóricas
Tienes limitaciones de memoria
Necesitas entrenar muchos modelos (AutoML, hyperparameter tuning extensivo)
Control del overfitting en leaf-wise growth
Debido al crecimiento leaf-wise más agresivo, LightGBM puede sobreajustar más fácilmente. Contrólalo con:
num_leaves: Reduce si hay overfitting (típicamente 20-50)
min_data_in_leaf: Aumenta (típicamente 20-100)
max_depth: Limita la profundidad (-1 = sin límite)
lambda_l1, lambda_l2: Aumenta regularización
bagging_fraction: Usa <1.0 para añadir randomness
5.3 CatBoost (Categorical Boosting)
CatBoost, desarrollado por Yandex en 2017, es una implementación de gradient boosting que destaca por dos características principales: su manejo excepcional de features categóricas y su robustez con parámetros por defecto. El nombre “CatBoost” viene de “Category Boosting”, reflejando su especialización en datos categóricos.
Una de las ventajas más apreciadas de CatBoost es que típicamente requiere muy poco tuning de hiperparámetros y produce buenos resultados “out of the box”, lo que lo hace excelente para producción y para usuarios que no tienen tiempo para optimización extensiva.
Innovaciones clave de CatBoost
1. Ordered Boosting
Una de las innovaciones más importantes de CatBoost es su solución al problema del prediction shift:
El problema del prediction shift:
En gradient boosting tradicional, calculamos los gradientes usando predicciones del modelo actual
Pero esas predicciones fueron generadas usando las mismas observaciones que ahora estamos usando para entrenar
Esto introduce un bias sutil: el modelo está “overfitting” a las observaciones de entrenamiento
Solución de CatBoost - Ordered Boosting:
Usa diferentes permutaciones aleatorias del dataset para diferentes árboles
Para predecir la observación \(i\), solo usa información de observaciones que aparecen antes de \(i\) en la permutación
Esto simula el proceso de predicción en datos nuevos
La intuición es similar a time series forecasting: no puedes usar información del futuro para predecir el pasado.
2. Manejo nativo de categorical features
CatBoost tiene el mejor manejo de features categóricas entre todas las implementaciones de boosting:
Problema con one-hot encoding:
Explota la dimensionalidad con categorías high-cardinality
Pierde información de frecuencias
No funciona bien con categorías raras
Problema con label encoding (1, 2, 3, …):
Introduce orden artificial
No captura relación con el target
Solución de CatBoost - Target Statistics con Ordered TS:
Para cada categoría, calcula estadísticas del target (e.g., promedio), pero de manera ordenada:
random_strength: Cantidad de randomness en splits (default = 1.0)
bagging_temperature: Controla la intensidad del Bayesian bootstrap
Categorical features:
cat_features: Índices o nombres de features categóricas
one_hot_max_size: Máximo número de categorías para usar one-hot en lugar de target statistics (default = 2)
Otros:
task_type: ‘CPU’ o ‘GPU’
verbose: Nivel de output durante entrenamiento
Learning rate automático
Si no especificas learning_rate, CatBoost lo selecciona automáticamente basándose en el número de iteraciones y el tamaño del dataset. Esta es una de las características que hacen a CatBoost “low-maintenance”.
Ejemplos prácticos con CatBoost
Comencemos con un ejemplo mostrando el manejo de categorical features:
from catboost import CatBoostRegressor, Poolimport warningswarnings.filterwarnings('ignore')# Crear dataset realista con categoríasnp.random.seed(42)n =2000# Features categóricas realistasdepartments = np.random.choice(['Sales', 'Engineering', 'Marketing', 'HR', 'Finance'], n)locations = np.random.choice(['NY', 'SF', 'Austin', 'Seattle', 'Boston', 'Chicago'], n)education = np.random.choice(['HS', 'Bachelor', 'Master', 'PhD'], n)# Mapeo para crear target realistadept_effect = {'Sales': 50000, 'Engineering': 90000, 'Marketing': 60000,'HR': 55000, 'Finance': 70000}loc_effect = {'NY': 20000, 'SF': 25000, 'Austin': 5000,'Seattle': 15000, 'Boston': 12000, 'Chicago': 8000}edu_effect = {'HS': 0, 'Bachelor': 15000, 'Master': 30000, 'PhD': 45000}# Features numéricasyears_exp = np.random.exponential(5, n)age = np.random.normal(35, 10, n)age = np.clip(age, 22, 65)# Target: salarysalary = ( np.array([dept_effect[d] for d in departments]) + np.array([loc_effect[l] for l in locations]) + np.array([edu_effect[e] for e in education]) + years_exp *2000+ (age -22) *500+ np.random.normal(0, 8000, n))# Crear DataFramedf_salary = pd.DataFrame({'department': departments,'location': locations,'education': education,'years_experience': years_exp,'age': age,'salary': salary})# Splittrain_df_sal, test_df_sal = train_test_split(df_salary, test_size=0.2, random_state=42)# Método 1: XGBoost con one-hot encodingX_train_ohe = pd.get_dummies( train_df_sal.drop('salary', axis=1), columns=['department', 'location', 'education'])X_test_ohe = pd.get_dummies( test_df_sal.drop('salary', axis=1), columns=['department', 'location', 'education'])X_test_ohe = X_test_ohe.reindex(columns=X_train_ohe.columns, fill_value=0)start = time.time()xgb_ohe = xgb.XGBRegressor(n_estimators=100, random_state=42, verbosity=0)xgb_ohe.fit(X_train_ohe, train_df_sal['salary'])time_xgb_ohe = time.time() - startscore_xgb_ohe = xgb_ohe.score(X_test_ohe, test_df_sal['salary'])# Método 2: CatBoost con categorical features nativasX_train_cat_sal = train_df_sal.drop('salary', axis=1)X_test_cat_sal = test_df_sal.drop('salary', axis=1)y_train_sal = train_df_sal['salary']y_test_sal = test_df_sal['salary']cat_features_list = ['department', 'location', 'education']start = time.time()cat_model = CatBoostRegressor( iterations=100, random_state=42, verbose=0)cat_model.fit( X_train_cat_sal, y_train_sal, cat_features=cat_features_list)time_cat = time.time() - startscore_cat = cat_model.score(X_test_cat_sal, y_test_sal)# Visualizar comparaciónfig, axes = plt.subplots(1, 3, figsize=(15, 4))methods = ['XGBoost\n(One-hot)', 'CatBoost\n(Native)']times = [time_xgb_ohe, time_cat]scores = [score_xgb_ohe, score_cat]n_features = [X_train_ohe.shape[1], X_train_cat_sal.shape[1]]# Tiempoaxes[0].bar(methods, times, color=['#e74c3c', '#f39c12'])axes[0].set_ylabel('Tiempo (segundos)')axes[0].set_title('Tiempo de Entrenamiento')for i, t inenumerate(times): axes[0].text(i, t +0.01, f'{t:.3f}s', ha='center')# Scoreaxes[1].bar(methods, scores, color=['#e74c3c', '#f39c12'])axes[1].set_ylabel('R² Score')axes[1].set_title('Precisión del Modelo')for i, s inenumerate(scores): axes[1].text(i, s -0.02, f'{s:.4f}', ha='center')# Número de featuresaxes[2].bar(methods, n_features, color=['#e74c3c', '#f39c12'])axes[2].set_ylabel('Número de Features')axes[2].set_title('Dimensionalidad')for i, n inenumerate(n_features): axes[2].text(i, n +0.5, f'{n}', ha='center')plt.tight_layout()plt.show()print("\nComparación:")print(f"XGBoost (one-hot): {n_features[0]} features, R² = {score_xgb_ohe:.4f}, {time_xgb_ohe:.3f}s")print(f"CatBoost (native): {n_features[1]} features, R² = {score_cat:.4f}, {time_cat:.3f}s")
Manejo automático de features categóricas en CatBoost
Manejo robusto de datos: Categorical features sin preprocesamiento
Pocos hiperparámetros críticos: Menos cosas pueden salir mal
Modelo más estable: Menos sensible a cambios en datos de entrada
CatBoost tiene soporte de GPU integrado, se activa automáticamente si está disponible o puedes especificar task_type='GPU'. :::
5.4 Análisis Comparativo
Ahora que hemos explorado XGBoost, LightGBM y CatBoost en detalle, realicemos un análisis comparativo comprehensivo para entender cuándo usar cada uno. Cada implementación tiene sus fortalezas y casos de uso ideales.
Tabla comparativa de características
Característica
sklearn GB
XGBoost
LightGBM
CatBoost
Velocidad de entrenamiento
Lento (1x)
Rápido (5-10x)
Muy rápido (10-15x)
Rápido (3-7x)
Velocidad de predicción
Media
Rápida
Muy rápida
Muy rápida
Uso de memoria
Alto
Medio
Bajo
Medio
Precisión (accuracy)
Buena
Excelente
Excelente
Excelente
Categorical features nativas
No
No*
Sí (básico)
Sí (avanzado)
Missing values handling
No
Sí
Sí
Sí
Soporte GPU
No
Sí
Sí
Sí
Regularización
Básica
Avanzada (L1+L2)
Media (L1+L2)
Muy avanzada
Hiperparámetros
Pocos
Muchos
Muchos
Medios
Facilidad de uso
Fácil
Media
Media
Fácil
Documentación
Excelente
Muy buena
Buena
Muy buena
Comunidad
Grande
Muy grande
Grande
Media-grande
Tuning requerido
Bajo
Alto
Alto
Bajo
Estabilidad
Muy alta
Alta
Alta
Muy alta
*XGBoost puede manejar categorías via one-hot encoding o con enable_categorical (experimental)
Benchmark comprehensivo
Realicemos un benchmark completo comparando las cuatro implementaciones en el mismo dataset:
from sklearn.ensemble import GradientBoostingRegressorfrom sklearn.metrics import mean_squared_error, r2_score, mean_absolute_errorimport time# Usar California Housing para benchmarkX_bench, y_bench = X_house, y_houseX_train_bench, X_test_bench, y_train_bench, y_test_bench = train_test_split( X_bench, y_bench, test_size=0.2, random_state=42)# Configuración comúnn_est =200lr =0.1depth =5results = {}# 1. sklearn GradientBoostingprint("Benchmarking sklearn GradientBoosting...")start = time.time()gb_sk = GradientBoostingRegressor( n_estimators=n_est, learning_rate=lr, max_depth=depth, random_state=42)gb_sk.fit(X_train_bench, y_train_bench)time_train_sk = time.time() - startstart = time.time()y_pred_sk = gb_sk.predict(X_test_bench)time_pred_sk = time.time() - startresults['sklearn'] = {'train_time': time_train_sk,'pred_time': time_pred_sk,'rmse': np.sqrt(mean_squared_error(y_test_bench, y_pred_sk)),'mae': mean_absolute_error(y_test_bench, y_pred_sk),'r2': r2_score(y_test_bench, y_pred_sk)}# 2. XGBoostprint("Benchmarking XGBoost...")start = time.time()xgb_bench = xgb.XGBRegressor( n_estimators=n_est, learning_rate=lr, max_depth=depth, random_state=42, verbosity=0)xgb_bench.fit(X_train_bench, y_train_bench)time_train_xgb = time.time() - startstart = time.time()y_pred_xgb = xgb_bench.predict(X_test_bench)time_pred_xgb = time.time() - startresults['XGBoost'] = {'train_time': time_train_xgb,'pred_time': time_pred_xgb,'rmse': np.sqrt(mean_squared_error(y_test_bench, y_pred_xgb)),'mae': mean_absolute_error(y_test_bench, y_pred_xgb),'r2': r2_score(y_test_bench, y_pred_xgb)}# 3. LightGBMprint("Benchmarking LightGBM...")start = time.time()lgb_bench = lgb.LGBMRegressor( n_estimators=n_est, learning_rate=lr, num_leaves=2**depth -1, # Aproximadamente equivalente random_state=42, verbose=-1)lgb_bench.fit(X_train_bench, y_train_bench)time_train_lgb = time.time() - startstart = time.time()y_pred_lgb = lgb_bench.predict(X_test_bench)time_pred_lgb = time.time() - startresults['LightGBM'] = {'train_time': time_train_lgb,'pred_time': time_pred_lgb,'rmse': np.sqrt(mean_squared_error(y_test_bench, y_pred_lgb)),'mae': mean_absolute_error(y_test_bench, y_pred_lgb),'r2': r2_score(y_test_bench, y_pred_lgb)}# 4. CatBoostprint("Benchmarking CatBoost...")start = time.time()cat_bench = CatBoostRegressor( iterations=n_est, learning_rate=lr, depth=depth, random_state=42, verbose=0)cat_bench.fit(X_train_bench, y_train_bench)time_train_cat = time.time() - startstart = time.time()y_pred_cat = cat_bench.predict(X_test_bench)time_pred_cat = time.time() - startresults['CatBoost'] = {'train_time': time_train_cat,'pred_time': time_pred_cat,'rmse': np.sqrt(mean_squared_error(y_test_bench, y_pred_cat)),'mae': mean_absolute_error(y_test_bench, y_pred_cat),'r2': r2_score(y_test_bench, y_pred_cat)}# Visualizar resultadosfig, axes = plt.subplots(2, 2, figsize=(14, 10))models =list(results.keys())colors = ['#3498db', '#e74c3c', '#16a085', '#f39c12']# Tiempo de entrenamientotrain_times = [results[m]['train_time'] for m in models]axes[0, 0].bar(models, train_times, color=colors)axes[0, 0].set_ylabel('Segundos')axes[0, 0].set_title('Tiempo de Entrenamiento')for i, t inenumerate(train_times): axes[0, 0].text(i, t +0.1, f'{t:.2f}s', ha='center')axes[0, 0].grid(axis='y', alpha=0.3)# Tiempo de predicción (ms)pred_times = [results[m]['pred_time'] *1000for m in models]axes[0, 1].bar(models, pred_times, color=colors)axes[0, 1].set_ylabel('Milisegundos')axes[0, 1].set_title('Tiempo de Predicción')for i, t inenumerate(pred_times): axes[0, 1].text(i, t +0.5, f'{t:.1f}ms', ha='center')axes[0, 1].grid(axis='y', alpha=0.3)# RMSErmses = [results[m]['rmse'] for m in models]axes[1, 0].bar(models, rmses, color=colors)axes[1, 0].set_ylabel('RMSE')axes[1, 0].set_title('Error (RMSE) - Menor es mejor')for i, r inenumerate(rmses): axes[1, 0].text(i, r +0.005, f'{r:.4f}', ha='center')axes[1, 0].grid(axis='y', alpha=0.3)# R² Scorer2s = [results[m]['r2'] for m in models]axes[1, 1].bar(models, r2s, color=colors)axes[1, 1].set_ylabel('R² Score')axes[1, 1].set_title('Precisión (R²) - Mayor es mejor')axes[1, 1].set_ylim([0.75, 0.85])for i, r inenumerate(r2s): axes[1, 1].text(i, r +0.003, f'{r:.4f}', ha='center')axes[1, 1].grid(axis='y', alpha=0.3)plt.tight_layout()plt.show()# Tabla resumenprint("\n"+"="*80)print("RESUMEN DE BENCHMARK")print("="*80)print(f"{'Modelo':<15}{'Train (s)':<12}{'Pred (ms)':<12}{'RMSE':<10}{'MAE':<10}{'R²':<10}")print("-"*80)for model in models: r = results[model]print(f"{model:<15}{r['train_time']:>10.2f}{r['pred_time']*1000:>10.1f} "f"{r['rmse']:>9.4f}{r['mae']:>9.4f}{r['r2']:>9.4f}")print("-"*80)# Speedups relativos a sklearnprint(f"\nSpeedups relativos a sklearn GradientBoosting:")for model in models[1:]: # Skip sklearn speedup = results['sklearn']['train_time'] / results[model]['train_time']print(f" {model}: {speedup:.2f}x más rápido")
Benchmark comprehensivo de las cuatro implementaciones de boosting
================================================================================
RESUMEN DE BENCHMARK
================================================================================
Modelo Train (s) Pred (ms) RMSE MAE R²
--------------------------------------------------------------------------------
sklearn 8.65 15.1 0.4736 0.3144 0.8288
XGBoost 0.22 2.5 0.4742 0.3124 0.8284
LightGBM 0.63 9.6 0.4483 0.2941 0.8466
CatBoost 0.19 0.9 0.4905 0.3313 0.8164
--------------------------------------------------------------------------------
Speedups relativos a sklearn GradientBoosting:
XGBoost: 38.99x más rápido
LightGBM: 13.79x más rápido
CatBoost: 46.18x más rápido
Ahora veamos un análisis de acuerdo en predicciones entre los modelos:
# Crear DataFrame con todas las prediccionespredictions_df = pd.DataFrame({'True': y_test_bench,'sklearn': y_pred_sk,'XGBoost': y_pred_xgb,'LightGBM': y_pred_lgb,'CatBoost': y_pred_cat})# Calcular correlaciones entre prediccionespred_corr = predictions_df.corr()# Visualizar matriz de correlaciónfig, axes = plt.subplots(1, 2, figsize=(14, 5))# Heatmap de correlacionesimport matplotlib.pyplot as pltfrom matplotlib.colors import LinearSegmentedColormapim = axes[0].imshow(pred_corr, cmap='RdYlGn', vmin=0.95, vmax=1.0)axes[0].set_xticks(range(len(pred_corr.columns)))axes[0].set_yticks(range(len(pred_corr.columns)))axes[0].set_xticklabels(pred_corr.columns, rotation=45, ha='right')axes[0].set_yticklabels(pred_corr.columns)axes[0].set_title('Correlación entre Predicciones')# Anotar valoresfor i inrange(len(pred_corr)):for j inrange(len(pred_corr)): text = axes[0].text(j, i, f'{pred_corr.iloc[i, j]:.4f}', ha="center", va="center", color="black", fontsize=9)plt.colorbar(im, ax=axes[0])# Scatter plot comparando las implementaciones modernasaxes[1].scatter(y_pred_xgb, y_pred_lgb, alpha=0.3, s=20, label='XGB vs LGB', color='#3498db')axes[1].scatter(y_pred_xgb, y_pred_cat, alpha=0.3, s=20, label='XGB vs Cat', color='#e74c3c')axes[1].plot([y_test_bench.min(), y_test_bench.max()], [y_test_bench.min(), y_test_bench.max()],'k--', lw=2, label='Acuerdo perfecto')axes[1].set_xlabel('XGBoost Predictions')axes[1].set_ylabel('Other Model Predictions')axes[1].set_title('Acuerdo entre Predicciones')axes[1].legend()axes[1].grid(alpha=0.3)plt.tight_layout()plt.show()print("\nNivel de acuerdo entre modelos (correlación):")print("Un valor cercano a 1.0 indica que los modelos hacen predicciones muy similares")print("\nCorrelaciones con el valor verdadero:")for model in ['sklearn', 'XGBoost', 'LightGBM', 'CatBoost']: corr = pred_corr.loc['True', model]print(f" {model:12s}: {corr:.6f}")
Acuerdo entre predicciones de diferentes implementaciones
Nivel de acuerdo entre modelos (correlación):
Un valor cercano a 1.0 indica que los modelos hacen predicciones muy similares
Correlaciones con el valor verdadero:
sklearn : 0.910423
XGBoost : 0.910177
LightGBM : 0.920144
CatBoost : 0.903648
Finalmente, comparemos la estabilidad de feature importance:
# Obtener feature importances de cada modeloimportances_dict = {'XGBoost': xgb_bench.feature_importances_,'LightGBM': lgb_bench.feature_importances_,'CatBoost': cat_bench.feature_importances_}# Normalizar importances (suma = 1)for model in importances_dict: importances_dict[model] = importances_dict[model] / importances_dict[model].sum()# Crear DataFrameimp_comparison = pd.DataFrame(importances_dict, index=X_bench.columns)# Visualizarfig, axes = plt.subplots(1, 2, figsize=(14, 5))# Barras agrupadasx = np.arange(len(imp_comparison))width =0.25axes[0].bar(x - width, imp_comparison['XGBoost'], width, label='XGBoost', color='#e74c3c', alpha=0.8)axes[0].bar(x, imp_comparison['LightGBM'], width, label='LightGBM', color='#16a085', alpha=0.8)axes[0].bar(x + width, imp_comparison['CatBoost'], width, label='CatBoost', color='#f39c12', alpha=0.8)axes[0].set_xlabel('Feature')axes[0].set_ylabel('Importance (normalizada)')axes[0].set_title('Comparación de Feature Importance')axes[0].set_xticks(x)axes[0].set_xticklabels(imp_comparison.index, rotation=45, ha='right')axes[0].legend()axes[0].grid(axis='y', alpha=0.3)# Correlaciones entre importancesimp_corr = imp_comparison.corr()im = axes[1].imshow(imp_corr, cmap='RdYlGn', vmin=0.8, vmax=1.0)axes[1].set_xticks(range(len(imp_corr.columns)))axes[1].set_yticks(range(len(imp_corr.columns)))axes[1].set_xticklabels(imp_corr.columns, rotation=45, ha='right')axes[1].set_yticklabels(imp_corr.columns)axes[1].set_title('Correlación entre Feature Importances')for i inrange(len(imp_corr)):for j inrange(len(imp_corr)): text = axes[1].text(j, i, f'{imp_corr.iloc[i, j]:.3f}', ha="center", va="center", color="black", fontsize=11)plt.colorbar(im, ax=axes[1])plt.tight_layout()plt.show()print("\nTop 3 features por modelo:")for model in ['XGBoost', 'LightGBM', 'CatBoost']: top_3 = imp_comparison[model].nlargest(3)print(f"\n{model}:")for feat, imp in top_3.items():print(f" {feat:15s}: {imp:.4f}")
Comparación de feature importance entre implementaciones
Top 3 features por modelo:
XGBoost:
MedInc : 0.5489
AveOccup : 0.1422
Longitude : 0.0860
LightGBM:
Longitude : 0.1907
Latitude : 0.1903
AveOccup : 0.1288
CatBoost:
MedInc : 0.3878
Latitude : 0.2043
Longitude : 0.1733
Guía de selección
Con base en el análisis anterior, aquí hay una guía para elegir la implementación adecuada:
Elige XGBoost si:
🎯 Uso general: Es tu primera vez con boosting avanzado
🏆 Competencias: Participas en Kaggle u otras competencias
📚 Documentación: Necesitas documentación extensa y ejemplos
🔧 Flexibilidad: Quieres custom objectives o métricas personalizadas
👥 Comunidad: Prefieres la comunidad más grande y establecida
⚖️ Balance: Necesitas buen balance entre velocidad y precisión
Elige LightGBM si:
⚡ Velocidad: La velocidad de entrenamiento es crítica
📊 Datos grandes: Tienes >50,000 muestras y >100 features
💾 Memoria limitada: Tienes restricciones de memoria
🔄 Iteración rápida: Necesitas experimentar con muchos modelos
🎛️ AutoML: Estás construyendo sistemas de AutoML
📈 Sparse features: Tienes features muy sparse
Elige CatBoost si:
🏷️ Categorías: Tienes muchas features categóricas (especialmente high-cardinality)
⏱️ Poco tiempo: No tienes tiempo para tuning extensivo
🎯 Defaults robustos: Quieres buenos resultados sin mucho esfuerzo
🚀 Producción: Vas a deployar a producción (predicción rápida)
🔒 Estabilidad: Priorizas reproducibilidad y estabilidad
📦 Out-of-the-box: Prefieres que “funcione bien” desde el inicio
Estrategia práctica
En la práctica, muchos científicos de datos prueban las tres implementaciones modernas (XGBoost, LightGBM, CatBoost) y seleccionan la que mejor funciona para su problema específico. Las diferencias de rendimiento suelen ser pequeñas, pero consistentes.
Una buena estrategia es:
Comenzar con CatBoost (defaults robustos)
Si la velocidad es un problema, probar LightGBM
Si necesitas más control/flexibilidad, probar XGBoost
Comparar los tres con cross-validation
Ensemble de ensembles
Un enfoque avanzado es usar stacking o voting combinando XGBoost, LightGBM y CatBoost. Como sus predicciones están altamente correlacionadas pero no son idénticas, un meta-modelo puede aprender a combinarlas efectivamente, típicamente ganando 0.5-1% en accuracy.
Para comenzar: Usa XGBoost. Tiene el mejor balance entre rendimiento, documentación y comunidad.
Para producción: CatBoost o LightGBM, dependiendo de si tienes muchas categorías (CatBoost) o priorizas velocidad (LightGBM).
Para competencias: Prueba los tres y combínalos con stacking o voting.
Para aprendizaje: Empieza con sklearn GradientBoosting para entender conceptos, luego pasa a las implementaciones modernas.
Independientemente de la elección, todos estos métodos son órdenes de magnitud mejores que modelos simples para la mayoría de problemas de datos tabulares, y la diferencia entre ellos es típicamente menor que la diferencia que puedes lograr con mejor ingeniería de features o más datos.
6. Hiperparámetros y Regularización
Los algoritmos de boosting tienen numerosos hiperparámetros que controlan el comportamiento del modelo. Entender qué hace cada uno y cómo afectan el rendimiento es crucial para usar boosting efectivamente. En esta sección exploraremos los hiperparámetros más importantes y su impacto en el aprendizaje del modelo.
A diferencia de Random Forest que es relativamente robusto a la elección de hiperparámetros, los modelos de boosting son más sensibles y requieren más atención. Sin embargo, esta sensibilidad también permite un control más fino del comportamiento del modelo.
Sobre la optimización de hiperparámetros
En esta sección nos enfocaremos en entender qué hace cada hiperparámetro y visualizar sus efectos. Las técnicas de optimización sistemática de hiperparámetros (Grid Search, Random Search, Bayesian Optimization) se cubrirán en un capítulo posterior dedicado a este tema.
6.1 Learning Rate (Tasa de Aprendizaje)
El learning rate (también llamado \(\eta\) o eta en XGBoost, learning_rate en sklearn/LightGBM/CatBoost) es probablemente el hiperparámetro más importante en boosting. Controla cuánto contribuye cada árbol nuevo al modelo total.
donde \(\nu\) es el learning rate (típicamente entre 0.01 y 0.3).
Intuición: - Learning rate bajo (e.g., 0.01): Cada árbol hace correcciones pequeñas → aprendizaje lento pero cuidadoso - Learning rate alto (e.g., 0.5-1.0): Cada árbol hace correcciones grandes → aprendizaje rápido pero puede sobreajustar
Trade-off fundamental: - Learning rate bajo + muchos árboles = mejor generalización, más tiempo de entrenamiento - Learning rate alto + pocos árboles = rápido pero puede sobreajustar
Visualicemos el efecto del learning rate:
# Crear dataset para visualizaciónnp.random.seed(42)X_lr = np.linspace(0, 10, 200).reshape(-1, 1)y_lr = np.sin(X_lr).ravel() + np.random.normal(0, 0.2, X_lr.shape[0])X_train_lr, X_test_lr, y_train_lr, y_test_lr = train_test_split( X_lr, y_lr, test_size=0.3, random_state=42)# Probar diferentes learning rateslearning_rates = [0.01, 0.05, 0.1, 0.3, 1.0]n_estimators_fixed =100fig, axes = plt.subplots(2, 3, figsize=(15, 10))axes = axes.ravel()for idx, lr inenumerate(learning_rates):# Entrenar modelo model = xgb.XGBRegressor( n_estimators=n_estimators_fixed, learning_rate=lr, max_depth=3, random_state=42, verbosity=0 )# Fit con eval_set para obtener curvas model.fit( X_train_lr, y_train_lr, eval_set=[(X_train_lr, y_train_lr), (X_test_lr, y_test_lr)], verbose=False )# Obtener errores por iteración results = model.evals_result() train_rmse = np.sqrt(results['validation_0']['rmse']) test_rmse = np.sqrt(results['validation_1']['rmse'])# Plot learning curves axes[idx].plot(train_rmse, label='Train', color='#3498db', linewidth=2) axes[idx].plot(test_rmse, label='Test', color='#e74c3c', linewidth=2) axes[idx].set_xlabel('Número de árboles') axes[idx].set_ylabel('RMSE') axes[idx].set_title(f'Learning Rate = {lr}') axes[idx].legend() axes[idx].grid(alpha=0.3)# Indicar si hay overfittingif test_rmse[-1] > test_rmse.min() *1.05: axes[idx].axvline(x=np.argmin(test_rmse), color='green', linestyle='--', alpha=0.7, label='Óptimo')# Remover último subplot vacíofig.delaxes(axes[-1])plt.tight_layout()plt.show()print("Observaciones:")print("- Learning rate muy bajo (0.01): Aprende lentamente, necesita más árboles")print("- Learning rate bajo-medio (0.05-0.1): Balance óptimo para este problema")print("- Learning rate alto (0.3-1.0): Aprende rápido pero sobreajusta")
Efecto del learning rate en el aprendizaje
Observaciones:
- Learning rate muy bajo (0.01): Aprende lentamente, necesita más árboles
- Learning rate bajo-medio (0.05-0.1): Balance óptimo para este problema
- Learning rate alto (0.3-1.0): Aprende rápido pero sobreajusta
Ahora veamos el trade-off entre learning rate y número de estimadores:
# Combinaciones de learning rate y n_estimators# Mantenemos el "presupuesto" de aprendizaje similarconfigs = [ {'lr': 0.01, 'n_est': 500, 'label': 'lr=0.01, n=500'}, {'lr': 0.05, 'n_est': 100, 'label': 'lr=0.05, n=100'}, {'lr': 0.1, 'n_est': 50, 'label': 'lr=0.1, n=50'}, {'lr': 0.3, 'n_est': 20, 'label': 'lr=0.3, n=20'},]fig, axes = plt.subplots(1, 2, figsize=(14, 5))colors = ['#3498db', '#2ecc71', '#f39c12', '#e74c3c']for idx, config inenumerate(configs): model = xgb.XGBRegressor( n_estimators=config['n_est'], learning_rate=config['lr'], max_depth=3, random_state=42, verbosity=0 ) model.fit( X_train_lr, y_train_lr, eval_set=[(X_train_lr, y_train_lr), (X_test_lr, y_test_lr)], verbose=False ) results = model.evals_result() test_rmse = np.sqrt(results['validation_1']['rmse'])# Plot 1: RMSE vs iterations axes[0].plot(test_rmse, label=config['label'], color=colors[idx], linewidth=2)# Plot 2: Final performance axes[1].bar(idx, test_rmse[-1], color=colors[idx], alpha=0.7) axes[1].text(idx, test_rmse[-1] +0.01,f"{test_rmse[-1]:.3f}", ha='center')axes[0].set_xlabel('Número de árboles')axes[0].set_ylabel('Test RMSE')axes[0].set_title('Curvas de Aprendizaje: LR vs N_estimators')axes[0].legend()axes[0].grid(alpha=0.3)axes[1].set_xticks(range(len(configs)))axes[1].set_xticklabels([c['label'] for c in configs], rotation=45, ha='right')axes[1].set_ylabel('RMSE Final')axes[1].set_title('Rendimiento Final')axes[1].grid(axis='y', alpha=0.3)plt.tight_layout()plt.show()print("\nConclusión:")print("Un learning rate más bajo con más árboles generalmente produce mejor")print("generalización, aunque requiere más tiempo de entrenamiento.")
Trade-off entre learning rate y número de estimadores
Conclusión:
Un learning rate más bajo con más árboles generalmente produce mejor
generalización, aunque requiere más tiempo de entrenamiento.
Regla práctica para learning rate
Desarrollo/experimentación: Usa learning_rate=0.1 con ~100 árboles para iterar rápido
Producción final: Reduce a learning_rate=0.01-0.05 con más árboles (500-1000+) para mejor rendimiento
Early stopping: Usa un learning rate bajo con muchos árboles y deja que early stopping encuentre el número óptimo
6.2 Número de Estimadores y Early Stopping
El número de estimadores (n_estimators, iterations) determina cuántos árboles secuenciales se construirán. Más árboles significan: - ✅ Modelo más expresivo, puede capturar patrones más complejos - ❌ Mayor riesgo de overfitting - ❌ Mayor tiempo de entrenamiento
Early Stopping es una técnica crucial que automáticamente detiene el entrenamiento cuando el rendimiento en un conjunto de validación deja de mejorar.
# Usar California Housing para ejemplo más realistaX_es, y_es = fetch_california_housing(return_X_y=True)X_train_es, X_temp, y_train_es, y_temp = train_test_split( X_es, y_es, test_size=0.3, random_state=42)X_val_es, X_test_es, y_val_es, y_test_es = train_test_split( X_temp, y_temp, test_size=0.5, random_state=42)# Modelo sin early stoppingmodel_no_es = xgb.XGBRegressor( n_estimators=500, learning_rate=0.1, max_depth=5, random_state=42, verbosity=0)model_no_es.fit( X_train_es, y_train_es, eval_set=[(X_train_es, y_train_es), (X_val_es, y_val_es)], verbose=False)# Modelo con early stoppingmodel_with_es = xgb.XGBRegressor( n_estimators=500, learning_rate=0.1, max_depth=5, early_stopping_rounds=20, random_state=42, verbosity=0)model_with_es.fit( X_train_es, y_train_es, eval_set=[(X_train_es, y_train_es), (X_val_es, y_val_es)], verbose=False)# Comparar resultadosresults_no_es = model_no_es.evals_result()results_with_es = model_with_es.evals_result()fig, axes = plt.subplots(1, 2, figsize=(14, 5))# Sin early stoppingtrain_rmse_no = np.sqrt(results_no_es['validation_0']['rmse'])val_rmse_no = np.sqrt(results_no_es['validation_1']['rmse'])axes[0].plot(train_rmse_no, label='Train', color='#3498db', linewidth=2)axes[0].plot(val_rmse_no, label='Validation', color='#e74c3c', linewidth=2)axes[0].axvline(x=np.argmin(val_rmse_no), color='green', linestyle='--', linewidth=2, label=f'Óptimo (iter {np.argmin(val_rmse_no)})')axes[0].set_xlabel('Número de árboles')axes[0].set_ylabel('RMSE')axes[0].set_title('Sin Early Stopping')axes[0].legend()axes[0].grid(alpha=0.3)# Con early stoppingtrain_rmse_with = np.sqrt(results_with_es['validation_0']['rmse'])val_rmse_with = np.sqrt(results_with_es['validation_1']['rmse'])axes[1].plot(train_rmse_with, label='Train', color='#3498db', linewidth=2)axes[1].plot(val_rmse_with, label='Validation', color='#e74c3c', linewidth=2)axes[1].axvline(x=model_with_es.best_iteration, color='green', linestyle='--', linewidth=2, label=f'Paró en iter {model_with_es.best_iteration}')axes[1].set_xlabel('Número de árboles')axes[1].set_ylabel('RMSE')axes[1].set_title('Con Early Stopping (20 rondas)')axes[1].legend()axes[1].grid(alpha=0.3)plt.tight_layout()plt.show()# Evaluar en test sety_pred_no_es = model_no_es.predict(X_test_es)y_pred_with_es = model_with_es.predict(X_test_es)rmse_no_es = np.sqrt(mean_squared_error(y_test_es, y_pred_no_es))rmse_with_es = np.sqrt(mean_squared_error(y_test_es, y_pred_with_es))print(f"\nRendimiento en Test Set:")print(f"Sin early stopping: RMSE = {rmse_no_es:.4f} (usó 500 árboles)")print(f"Con early stopping: RMSE = {rmse_with_es:.4f} (usó {model_with_es.best_iteration} árboles)")print(f"\nÁrboles ahorrados: {500- model_with_es.best_iteration}")print(f"Mejora en RMSE: {((rmse_no_es - rmse_with_es) / rmse_no_es *100):.2f}%")
Early stopping previene overfitting automáticamente
Rendimiento en Test Set:
Sin early stopping: RMSE = 0.4421 (usó 500 árboles)
Con early stopping: RMSE = 0.4421 (usó 499 árboles)
Árboles ahorrados: 1
Mejora en RMSE: 0.00%
Recomendación para early stopping
Siempre usa early stopping en producción:
Configura n_estimators alto (500-2000)
Usa early_stopping_rounds=20-50 (más alto si usas learning rate muy bajo)
Proporciona un conjunto de validación separado
El modelo se detendrá automáticamente en el punto óptimo
Esto previene overfitting y ahorra tiempo de entrenamiento sin necesidad de adivinar el número óptimo de árboles.
6.3 Parámetros de Estructura del Árbol
Los parámetros que controlan la estructura de cada árbol individual son cruciales para el balance bias-variance.
Principales parámetros:
max_depth: Profundidad máxima de cada árbol (típicamente 3-10)
min_child_weight (XGBoost) / min_samples_leaf (sklearn): Mínimo de muestras en una hoja
min_samples_split (sklearn/LightGBM): Mínimo de muestras para dividir un nodo
num_leaves (LightGBM): Número máximo de hojas (específico de leaf-wise growth)
Intuición: - Árboles poco profundos (depth 1-3): Alto bias, bajo variance → underfitting potencial - Árboles profundos (depth 8-15): Bajo bias, alto variance → overfitting potencial - Boosting típicamente usa árboles poco profundos (weak learners) para reducir bias gradualmente
# Probar diferentes profundidadesdepths = [1, 2, 3, 5, 7, 10]n_est =100fig, axes = plt.subplots(2, 3, figsize=(15, 10))axes = axes.ravel()for idx, depth inenumerate(depths): model = xgb.XGBRegressor( n_estimators=n_est, learning_rate=0.1, max_depth=depth, random_state=42, verbosity=0 ) model.fit( X_train_es, y_train_es, eval_set=[(X_train_es, y_train_es), (X_val_es, y_val_es)], verbose=False ) results = model.evals_result() train_rmse = np.sqrt(results['validation_0']['rmse']) val_rmse = np.sqrt(results['validation_1']['rmse']) axes[idx].plot(train_rmse, label='Train', color='#3498db', linewidth=2) axes[idx].plot(val_rmse, label='Validation', color='#e74c3c', linewidth=2) axes[idx].set_xlabel('Número de árboles') axes[idx].set_ylabel('RMSE') axes[idx].set_title(f'max_depth = {depth}') axes[idx].legend() axes[idx].grid(alpha=0.3)# Calcular gap entre train y validation (overfitting) gap = train_rmse[-1] - val_rmse[-1] axes[idx].text(0.02, 0.98, f'Gap: {gap:.3f}', transform=axes[idx].transAxes, va='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))plt.tight_layout()plt.show()print("\nObservaciones:")print("- depth=1 (stumps): Underfitting, alto error en train y validation")print("- depth=2-3: Buen balance, bajo overfitting")print("- depth=5-7: Empieza a sobreajustar (gap train-validation aumenta)")print("- depth=10: Severo overfitting, excelente en train, pobre en validation")
Efecto de la profundidad del árbol en el aprendizaje
Observaciones:
- depth=1 (stumps): Underfitting, alto error en train y validation
- depth=2-3: Buen balance, bajo overfitting
- depth=5-7: Empieza a sobreajustar (gap train-validation aumenta)
- depth=10: Severo overfitting, excelente en train, pobre en validation
Visualicemos el efecto en decision boundaries (problema de clasificación 2D):
Decision boundaries con diferentes profundidades de árbol
Interpretación:
- depth=1: Decision boundary muy simple, underfitting
- depth=2-3: Captura el patrón circular razonablemente
- depth=5: Boundary muy compleja, puede sobreajustar a ruido
Valores típicos recomendados
Para la mayoría de problemas, estos son buenos puntos de partida:
max_depth: 3-6 (XGBoost/sklearn), 5-8 (CatBoost con árboles oblivious)
num_leaves: 20-50 (LightGBM)
min_child_weight: 1-5 (más alto para datos ruidosos)
min_samples_leaf: 5-20 (sklearn)
Árboles más profundos pueden ser útiles con: - Datasets muy grandes (>100k muestras) - Muchas features informativas - Relaciones muy complejas - Cuando usas learning rate muy bajo y mucha regularización
6.4 Subsampling (Stochastic Gradient Boosting)
Similar a Random Forest, podemos añadir randomness al boosting muestreando observaciones y features. Esto reduce overfitting y puede acelerar el entrenamiento.
Parámetros de subsampling:
subsample / bagging_fraction: Fracción de observaciones a usar por árbol (0.5-1.0)
colsample_bytree / feature_fraction: Fracción de features a usar por árbol
colsample_bylevel: Fracción de features por nivel del árbol (XGBoost)
# Configuraciones de subsamplesubsample_configs = [ {'subsample': 1.0, 'colsample': 1.0, 'label': 'Sin subsample'}, {'subsample': 0.8, 'colsample': 1.0, 'label': 'Row subsample 0.8'}, {'subsample': 1.0, 'colsample': 0.8, 'label': 'Col subsample 0.8'}, {'subsample': 0.8, 'colsample': 0.8, 'label': 'Both subsample 0.8'},]fig, axes = plt.subplots(2, 2, figsize=(14, 10))axes = axes.ravel()for idx, config inenumerate(subsample_configs): model = xgb.XGBRegressor( n_estimators=200, learning_rate=0.1, max_depth=6, # Más profundo para ver efecto subsample=config['subsample'], colsample_bytree=config['colsample'], random_state=42, verbosity=0 ) model.fit( X_train_es, y_train_es, eval_set=[(X_train_es, y_train_es), (X_val_es, y_val_es)], verbose=False ) results = model.evals_result() train_rmse = np.sqrt(results['validation_0']['rmse']) val_rmse = np.sqrt(results['validation_1']['rmse']) axes[idx].plot(train_rmse, label='Train', color='#3498db', linewidth=2, alpha=0.7) axes[idx].plot(val_rmse, label='Validation', color='#e74c3c', linewidth=2) axes[idx].set_xlabel('Número de árboles') axes[idx].set_ylabel('RMSE') axes[idx].set_title(config['label']) axes[idx].legend() axes[idx].grid(alpha=0.3)# Mostrar gap gap = train_rmse[-1] - val_rmse[-1] axes[idx].text(0.98, 0.98, f'Overfitting gap: {gap:.3f}', transform=axes[idx].transAxes, ha='right', va='top', bbox=dict(boxstyle='round', facecolor='yellow', alpha=0.5))plt.tight_layout()plt.show()print("\nEfecto del subsampling:")print("- Sin subsample: Overfitting más pronunciado (gap grande)")print("- Con subsample: Reduce overfitting (gap menor)")print("- Subsample en rows y columns: Máxima regularización")print("\nEl subsample añade randomness que ayuda a generalizar mejor")
Efecto del subsampling en reducción de overfitting
Efecto del subsampling:
- Sin subsample: Overfitting más pronunciado (gap grande)
- Con subsample: Reduce overfitting (gap menor)
- Subsample en rows y columns: Máxima regularización
El subsample añade randomness que ayuda a generalizar mejor
Recomendaciones para subsampling
subsample=0.8: Buen balance entre velocidad y precisión
colsample_bytree=0.8-1.0: Especialmente útil con muchas features
Beneficios adicionales:
Reduce overfitting (efecto de regularización)
Acelera entrenamiento (procesa menos datos por árbol)
Añade diversity entre árboles (similar a Random Forest)
No uses valores muy bajos (<0.5) a menos que tengas un dataset muy grande.
6.5 Regularización
Los parámetros de regularización penalizan la complejidad del modelo, ayudando a prevenir overfitting.
Parámetros principales:
lambda / reg_lambda / l2_leaf_reg: Regularización L2 en pesos de hojas
alpha / reg_alpha: Regularización L1 en pesos de hojas
gamma / min_split_loss: Ganancia mínima requerida para hacer un split
# Probar diferentes valores de lambda (L2 regularization)lambda_values = [0, 0.1, 1, 5, 10]fig, axes = plt.subplots(2, 3, figsize=(15, 10))axes = axes.ravel()for idx, lam inenumerate(lambda_values): model = xgb.XGBRegressor( n_estimators=150, learning_rate=0.1, max_depth=6, # Árbol profundo para ver regularización reg_lambda=lam, random_state=42, verbosity=0 ) model.fit( X_train_es, y_train_es, eval_set=[(X_train_es, y_train_es), (X_val_es, y_val_es)], verbose=False ) results = model.evals_result() train_rmse = np.sqrt(results['validation_0']['rmse']) val_rmse = np.sqrt(results['validation_1']['rmse']) axes[idx].plot(train_rmse, label='Train', color='#3498db', linewidth=2) axes[idx].plot(val_rmse, label='Validation', color='#e74c3c', linewidth=2) axes[idx].set_xlabel('Número de árboles') axes[idx].set_ylabel('RMSE') axes[idx].set_title(f'lambda = {lam}') axes[idx].legend() axes[idx].grid(alpha=0.3)# Mejor validation RMSE best_val = np.min(val_rmse) axes[idx].text(0.02, 0.02, f'Best val: {best_val:.4f}', transform=axes[idx].transAxes, bbox=dict(boxstyle='round', facecolor='lightgreen', alpha=0.5))# Remover subplot vacíofig.delaxes(axes[-1])plt.tight_layout()plt.show()print("\nEfecto de la regularización L2 (lambda):")print("- lambda=0: Sin regularización, puede sobreajustar")print("- lambda=0.1-1: Regularización moderada, buen balance")print("- lambda=5-10: Regularización fuerte, puede underfit")print("\nLa regularización hace el modelo más conservador y robusto")
Efecto de la regularización L2 en el aprendizaje
Efecto de la regularización L2 (lambda):
- lambda=0: Sin regularización, puede sobreajustar
- lambda=0.1-1: Regularización moderada, buen balance
- lambda=5-10: Regularización fuerte, puede underfit
La regularización hace el modelo más conservador y robusto
Comparemos L1 vs L2 regularization:
configs_reg = [ {'alpha': 0, 'lambda': 0, 'label': 'Sin regularización'}, {'alpha': 0, 'lambda': 1, 'label': 'L2 (lambda=1)'}, {'alpha': 1, 'lambda': 0, 'label': 'L1 (alpha=1)'}, {'alpha': 1, 'lambda': 1, 'label': 'L1 + L2 (elastic net)'},]fig, axes = plt.subplots(1, 2, figsize=(14, 5))colors_reg = ['#e74c3c', '#3498db', '#2ecc71', '#f39c12']# Entrenar modelos y compararresults_summary = []for idx, config inenumerate(configs_reg): model = xgb.XGBRegressor( n_estimators=150, learning_rate=0.1, max_depth=6, reg_alpha=config['alpha'], reg_lambda=config['lambda'], random_state=42, verbosity=0 ) model.fit( X_train_es, y_train_es, eval_set=[(X_val_es, y_val_es)], verbose=False )# Evaluar en test y_pred = model.predict(X_test_es) test_rmse = np.sqrt(mean_squared_error(y_test_es, y_pred))# Feature sparsity (cuántas features tienen importancia ~0) importances = model.feature_importances_ sparsity = np.sum(importances <0.001) /len(importances) *100 results_summary.append({'label': config['label'],'test_rmse': test_rmse,'sparsity': sparsity })# Plot 1: Test RMSEtest_rmses = [r['test_rmse'] for r in results_summary]axes[0].bar(range(len(results_summary)), test_rmses, color=colors_reg, alpha=0.7)axes[0].set_xticks(range(len(results_summary)))axes[0].set_xticklabels([r['label'] for r in results_summary], rotation=45, ha='right')axes[0].set_ylabel('Test RMSE')axes[0].set_title('Rendimiento en Test Set')axes[0].grid(axis='y', alpha=0.3)for i, rmse inenumerate(test_rmses): axes[0].text(i, rmse +0.005, f'{rmse:.4f}', ha='center')# Plot 2: Feature sparsitysparsities = [r['sparsity'] for r in results_summary]axes[1].bar(range(len(results_summary)), sparsities, color=colors_reg, alpha=0.7)axes[1].set_xticks(range(len(results_summary)))axes[1].set_xticklabels([r['label'] for r in results_summary], rotation=45, ha='right')axes[1].set_ylabel('% Features con importancia ~0')axes[1].set_title('Sparsity de Features (Feature Selection)')axes[1].grid(axis='y', alpha=0.3)for i, sp inenumerate(sparsities): axes[1].text(i, sp +1, f'{sp:.1f}%', ha='center')plt.tight_layout()plt.show()print("\nDiferencias entre L1 y L2:")print("- L2 (Ridge): Reduce magnitud de todos los pesos proporcionalmente")print("- L1 (Lasso): Puede llevar algunos pesos exactamente a 0 (feature selection)")print("- L1 + L2 (Elastic Net): Combina ambos beneficios")
Comparación entre regularización L1 y L2
Diferencias entre L1 y L2:
- L2 (Ridge): Reduce magnitud de todos los pesos proporcionalmente
- L1 (Lasso): Puede llevar algunos pesos exactamente a 0 (feature selection)
- L1 + L2 (Elastic Net): Combina ambos beneficios
Cuándo usar más regularización
Aumenta la regularización cuando observes:
Gap grande entre training y validation error
El modelo es muy sensible a cambios pequeños en datos
Tienes muchas features de baja calidad o ruidosas
Dataset pequeño (<1000 muestras)
Reduce la regularización cuando:
Training error es alto (underfitting)
Tienes un dataset muy grande y limpio
Las features son todas informativas
6.6 Resumen de Hiperparámetros
Tabla resumen de efectos:
Hiperparámetro
↑ Aumentar el valor
↓ Disminuir el valor
learning_rate
Aprende más rápido, puede sobreajustar
Aprende más lento, mejor generalización
n_estimators
Más expresivo, riesgo de overfit
Más rápido, puede underfit
max_depth
Árboles más complejos, puede overfit
Árboles simples, puede underfit
subsample
Usa más datos, menos randomness
Más regularización, más rápido
colsample_bytree
Usa más features, menos randomness
Más regularización por feature
lambda (L2)
Más regularización (conservador)
Menos regularización (flexible)
alpha (L1)
Más sparsity (feature selection)
Menos sparsity
min_child_weight
Hojas más pobladas (conservador)
Hojas más específicas (flexible)
Configuración típica “robusta” para empezar:
# Configuración conservadora que generalmente funciona bienmodel = xgb.XGBRegressor( n_estimators=1000, # Alto, early stopping decidirá learning_rate=0.05, # Moderado max_depth=5, # Ni muy profundo ni muy shallow subsample=0.8, # Un poco de randomness colsample_bytree=0.8, # Un poco de randomness reg_lambda=1, # Regularización L2 moderada reg_alpha=0, # Sin L1 por defecto min_child_weight=3, # Hojas no demasiado pequeñas early_stopping_rounds=50, # Parar cuando deje de mejorar random_state=42)
Siguiente paso: Optimización sistemática
En esta sección hemos aprendido qué hace cada hiperparámetro y cómo afecta al modelo. Para problemas reales, querrás encontrar la mejor combinación de hiperparámetros para tus datos específicos.
Las técnicas de optimización sistemática de hiperparámetros (Grid Search, Random Search, Bayesian Optimization, Optuna, etc.) se cubrirán en detalle en un capítulo posterior dedicado a este tema.
7. Conclusiones
Los métodos de boosting representan uno de los avances más significativos en machine learning supervisado de las últimas décadas. A lo largo de este capítulo, hemos explorado desde los fundamentos teóricos hasta las implementaciones modernas más utilizadas en la industria.
Puntos clave
1. El concepto fundamental de boosting
Boosting es un método de aprendizaje secuencial que construye un modelo fuerte combinando múltiples modelos débiles. A diferencia de bagging y Random Forest que reducen varianza mediante promediado de modelos independientes, boosting reduce bias mediante corrección iterativa de errores:
Cada modelo se enfoca en los errores de los modelos anteriores
La combinación final es una suma ponderada de todos los modelos
Convierte “weak learners” en un “strong learner” con garantías teóricas
2. Familia de algoritmos
Hemos visto la evolución desde algoritmos clásicos hasta implementaciones modernas:
AdaBoost: El pionero, actualiza pesos de muestras, ideal para entender el concepto
Gradient Boosting: Generalización flexible que funciona con cualquier función de pérdida diferenciable
XGBoost: Velocidad + regularización avanzada, el estándar de la industria
LightGBM: Máxima velocidad y eficiencia en memoria, ideal para datasets grandes
CatBoost: Robustez y manejo nativo de categorías, excelente “out of the box”
3. Comparación con otros métodos ensemble
Aspecto
Bagging/RF
Boosting
Construcción
Paralela
Secuencial
Objetivo
↓ Varianza
↓ Bias
Base learners
Complejos (árboles profundos)
Simples (árboles shallow)
Velocidad
Rápido
Más lento
Overfitting
Bajo riesgo
Mayor riesgo
Sensibilidad a parámetros
Baja
Alta
Rendimiento típico
Muy bueno
Excelente
Boosting típicamente supera a Random Forest cuando: - Tienes tiempo para tuning de hiperparámetros - Los datos son relativamente limpios (no extremadamente ruidosos) - Priorizas precisión sobre velocidad de entrenamiento - Quieres extraer el máximo rendimiento posible
4. Hiperparámetros críticos
Los hiperparámetros más importantes que controlan el comportamiento del boosting son:
learning_rate + n_estimators → Control de aprendizaje
max_depth + min_child_weight → Complejidad de árboles
subsample + colsample_bytree → Regularización estocástica
lambda + alpha → Regularización de pesos
early_stopping → Prevención automática de overfitting
El balance adecuado entre estos parámetros determina si el modelo underfits, se generaliza bien, o sobreajusta.
Guía de decisión rápida
¿Cuándo usar boosting?
✅ Usa boosting cuando:
Trabajas con datos tabulares/estructurados
Necesitas el máximo rendimiento predictivo
Tienes features numéricas y categóricas bien definidas
Puedes dedicar tiempo a experimentación y tuning
El problema es de clasificación o regresión supervisada
❌ No uses boosting cuando:
Tienes muy pocos datos (< 100 muestras)
Los datos son extremadamente ruidosos
Trabajas con imágenes, texto, o señales (considera deep learning)
Necesitas entrenamiento en tiempo real
La interpretabilidad individual es crítica (usa modelos lineales o árboles simples)
¿Qué implementación elegir?
┌─ ¿Tienes muchas features categóricas?
│ └─ Sí → CatBoost
│ └─ No → Continúa
│
├─ ¿Dataset muy grande (>50k muestras, >100 features)?
│ └─ Sí → LightGBM
│ └─ No → Continúa
│
├─ ¿Primera vez con boosting o necesitas documentación extensa?
│ └─ Sí → XGBoost
│ └─ No → XGBoost igual (es el más versátil)
│
└─ Para aprendizaje: sklearn GradientBoosting
Recomendaciones prácticas finales
Para empezar:
Usa XGBoost con parámetros conservadores
Implementa early stopping con conjunto de validación
Compara con un baseline simple (regresión lineal o árbol único)
Visualiza learning curves para detectar overfitting
Para mejorar:
Experimenta con las tres implementaciones modernas (XGBoost, LightGBM, CatBoost)
Entiende el efecto de cada hiperparámetro principal
Usa cross-validation para evaluar robustez
Considera feature engineering (a menudo más importante que hiperparámetros)
Para producción:
Usa early stopping para evitar sobreajuste
Serializa modelos con pickle/joblib o formato nativo
Monitorea distribución de predicciones en producción
Documenta hiperparámetros y decisiones de diseño
Considera CatBoost por su robustez y velocidad de inferencia
El consejo más importante
En la práctica profesional, boosting + buenas features > boosting complejo + features mediocres.
Dedica más tiempo a:
Entender tus datos
Crear features informativas
Validar correctamente
Evitar data leakage
Y menos tiempo a:
Optimizar el último 0.1% de accuracy
Probar todas las combinaciones posibles de hiperparámetros
Usar arquitecturas excesivamente complejas
Recursos adicionales
Papers fundamentales:
Freund & Schapire (1997): “A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting” - AdaBoost original
Friedman (2001): “Greedy Function Approximation: A Gradient Boosting Machine” - Gradient Boosting
Chen & Guestrin (2016): “XGBoost: A Scalable Tree Boosting System” - XGBoost
Ke et al. (2017): “LightGBM: A Highly Efficient Gradient Boosting Decision Tree” - LightGBM
Prokhorenkova et al. (2018): “CatBoost: unbiased boosting with categorical features” - CatBoost
Kaggle competitions: Muchas competencias se ganan con boosting
UCI Machine Learning Repository: Datasets tabulares para experimentar
OpenML: Plataforma con datasets y benchmarks
Próximos pasos
Ahora que dominas los métodos de boosting, estás equipado para:
Aplicar boosting a problemas reales: Tanto en competencias como en proyectos profesionales
Combinar con otros métodos: Stacking, voting, o como parte de pipelines más complejos
Explorar variantes especializadas: Boosting para ranking, survival analysis, etc.
Avanzar a redes neuronales: Que veremos en el siguiente capítulo y son complementarias para otros tipos de datos
Boosting es una herramienta fundamental en el toolkit de cualquier científico de datos moderno. Con el conocimiento adquirido en este capítulo, tienes las bases sólidas para aplicarlo efectivamente y seguir explorando sus numerosas variantes y aplicaciones.
Ejercicios recomendados
Para consolidar tu aprendizaje:
Implementa un pipeline completo con uno de los datasets del curso usando XGBoost, LightGBM y CatBoost
Compara rendimiento de boosting vs Random Forest en el mismo problema
Visualiza el efecto de diferentes hiperparámetros en un problema de tu elección
Participa en una competencia de Kaggle usando métodos de boosting
Explora interpretabilidad usando SHAP values con modelos de boosting
Estos ejercicios te darán experiencia práctica invaluable que complementa la teoría de este capítulo.